在上一篇文章中测试了在ceph环境下,通过gdbprof分析4k-randwrite的性能,可以看出rocksdb线程耗用资源较多,因为ceph的底层就是基于rocksdb进行存储的,因此尝试着去调节ceph中导出的rocksdb参数,来达到一个调优效果。
简单查看下集群是否正常:
$ceph osd tree
 $ceph -s
$ceph -s

rocksdb导出参数
 接下来对参数进行说明:
接下来对参数进行说明:
“bluestore_rocksdb_options”: “compression=kNoCompression,max_write_buffer_number=4,min_write_buffer_number_to_merge=1,
recycle_log_file_num=4,write_buffer_size=268435456,writable_file_max_buffer_size=0,compaction_readahead_size=2097152”
Compression=kNoCompression:表示数据不进行压缩。对每个SST文件,数据块和索引块都会被单独压缩,默认是Snappy
write_buffer_size=268435456(2^28):memtable的最大size,如果超过这个值,RocksDB会将其变成immutable memtable,并使用另一个新的memtable。插入数据时RocksDB首先会将其放到memtable里,所以写入很快,当一个memtable full之后,RocksDB会将该memtable变成immutable,用另一个新的memtable来存储新的写入,immutable的memtable就被等待flush到level0
max_write_buffer_number=4:最大的memtable个数。如果active memtable都full了,并且active memtable+immutable memtable个数超过max_write_buffer_number,则RocksDB会停止写入,通常原因是写入太快而flush不及时造成的。
min_write_buffer_number_to_merge=1:在flush到level0之前,最少需要被merge的memtable个数,如min_write_buffer_number_to_merge =2,那么至少当有两个immutable的memtable时,RocksDB才会将这两个immutable memTable先merge,再flush到level0。Merge 的好处是,譬如在一个key在不同的memtable里都有修改,可以merge形成一次修改。min_write_buffer_number_to_merge太大会影响读取性能,因为Get会遍历所有的memtable来看该key是否存在。
compaction_readahead_size=2097152(2^21):预读大小,在进行compression时,执行更大的数据读取
writable_file_max_buffer_size=0:可写文件的最大写缓存
修改rocksdb参数
首先分为服务端机器server_host和客户端机器client_host
修改server_host的/etc/ceph/ceph.conf中bluestore rocksdb项
$vim /etc/ceph/ceph.conf
添加以下参数配置
[osd]
bluestore rocksdb options = compression=kNoCompression,max_write_buffer_number=8,min_write_buffer_number_to_merge=4,recycle_log_file_num=4,write_buffer_size=356870912,writable_file_max_buffer_size=0,compaction_readahead_size=8388608
[osd.0]
[osd.1]
[osd.2]
wq保存退出
重启osd集群
systemctl restart ceph-osd@0.service
systemctl restart ceph-osd@1.service
systemctl restart ceph-osd@2.service
注:osd一个一个的重启,不要快速重启三个,等一个osd重启并运行正常后(可用$ceph osd tree查看),再重启第二个,不然集群容易挂掉
查看rocksdb参数是否有变化
ceph daemon osd.0 config show | grep bluestore_rocksdb
ceph daemon osd.1 config show | grep bluestore_rocksdb
ceph daemon osd.2 config show | grep bluestore_rocksdb
FIO测试性能
(1)先创建image再进行4k-randwrite操作
$rbd create –pool ymg –image img01 –size 40G
(2)填充image
$fio -direct=1 -iodepth=256 -ioengine=rbd -pool=ymg -rbdname=img01 -rw=write -bs=1M -size=40G -ramp_time=5 -group_reporting -name=full-fill
(3)randwrite命令
$fio -direct=1 -iodepth=256 -ioengine=rbd -pool=ymg -rbdname=img01 -rw=randwrite -bs=4K -runtime=300 -numjobs=1 -ramp_time=5 -group_reporting -name=parameter1
对比实验及结果
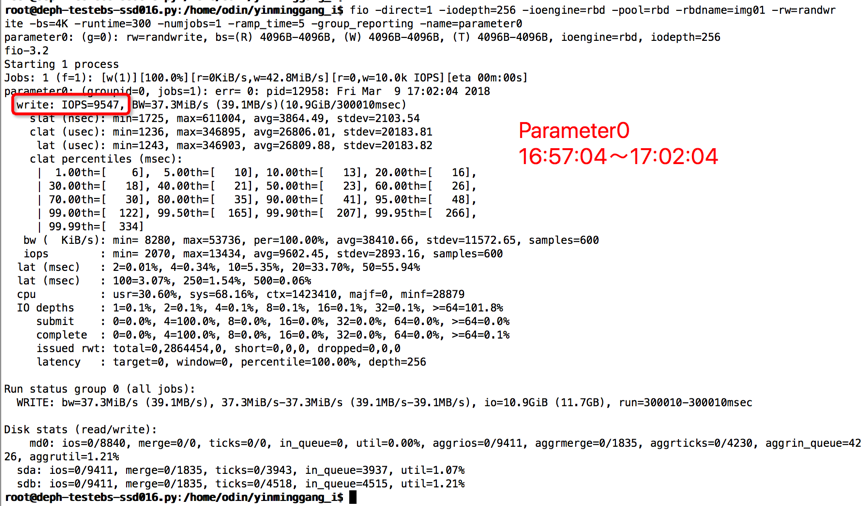
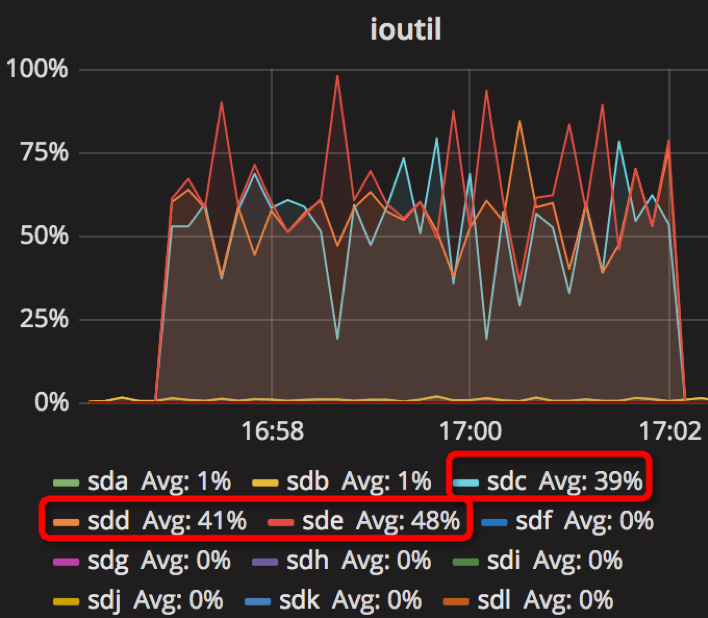
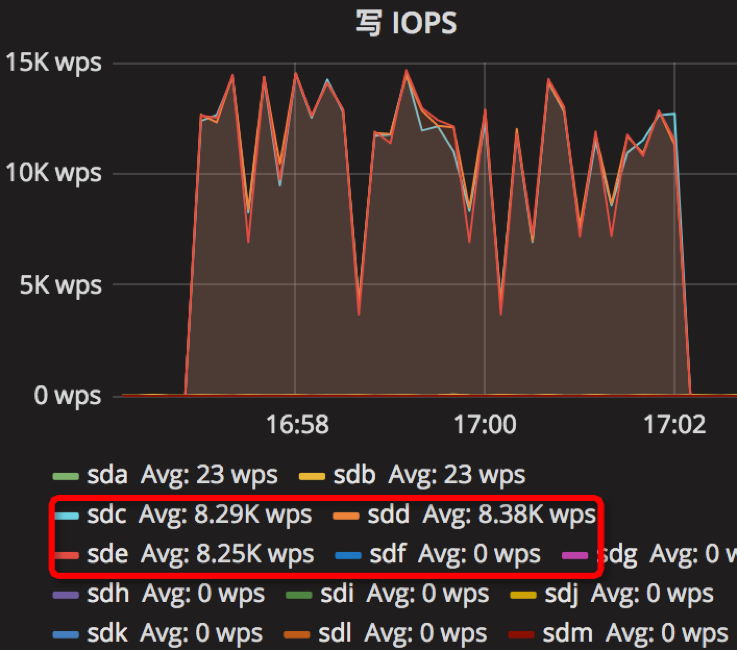
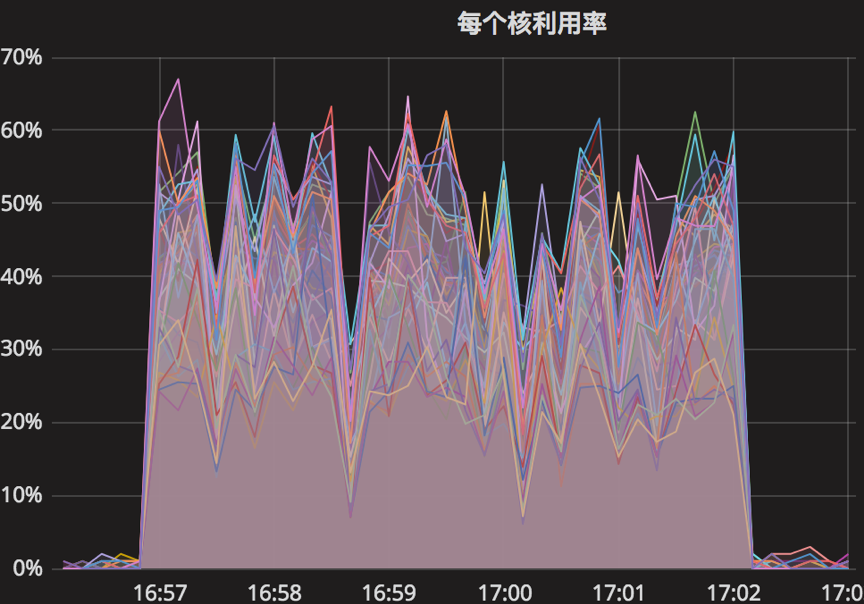
【Parameter0实验-原始参数】
compression=kNoCompression
max_write_buffer_number=4
min_write_buffer_number_to_merge=1
recycle_log_file_num=4
write_buffer_size=268435456
writable_file_max_buffer_size=0
compaction_readahead_size=2097152
时间段:16:57:04~17:02:04
结果如下

【Parameter1实验】
compression=kNoCompression
max_write_buffer_number=8
min_write_buffer_number_to_merge=4
recycle_log_file_num=4
write_buffer_size=536870912
writable_file_max_buffer_size=0
compaction_readahead_size=8388608
时间段:17:16:00~17:21:00
结果如下
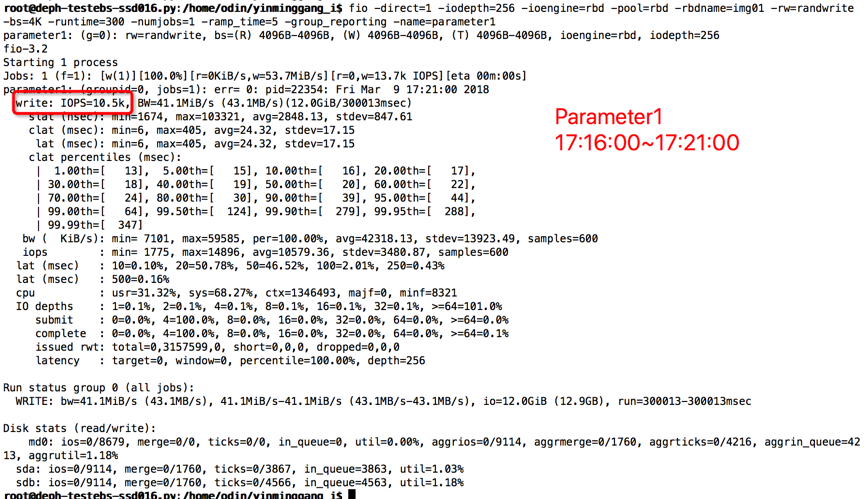
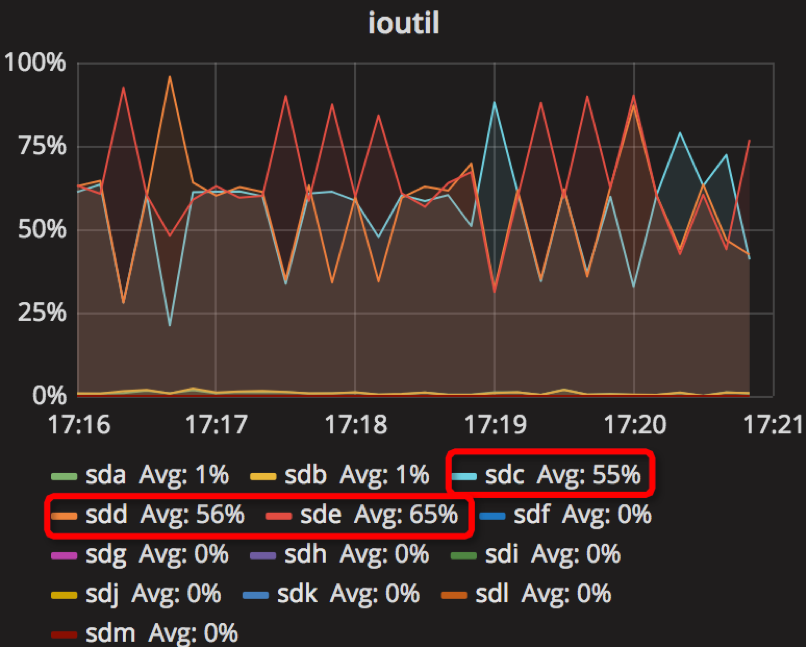

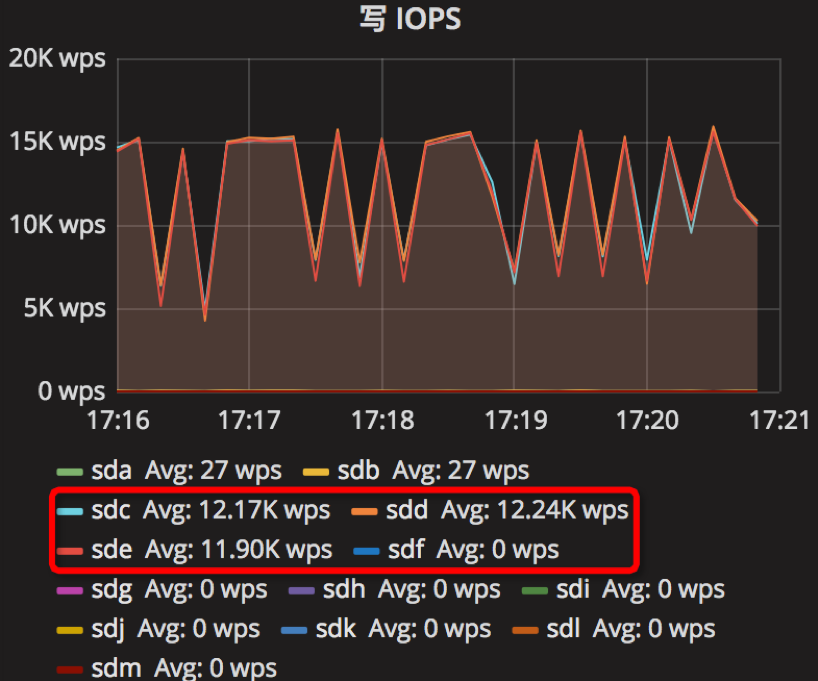
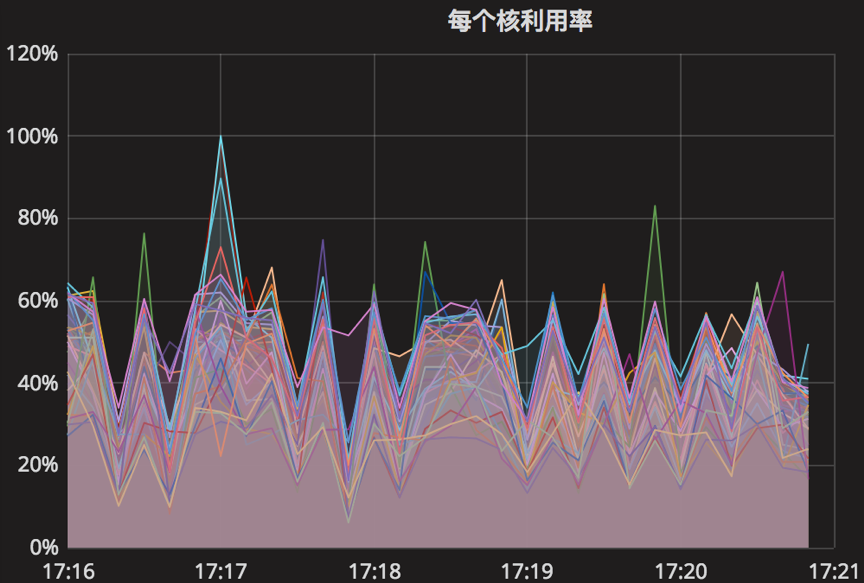
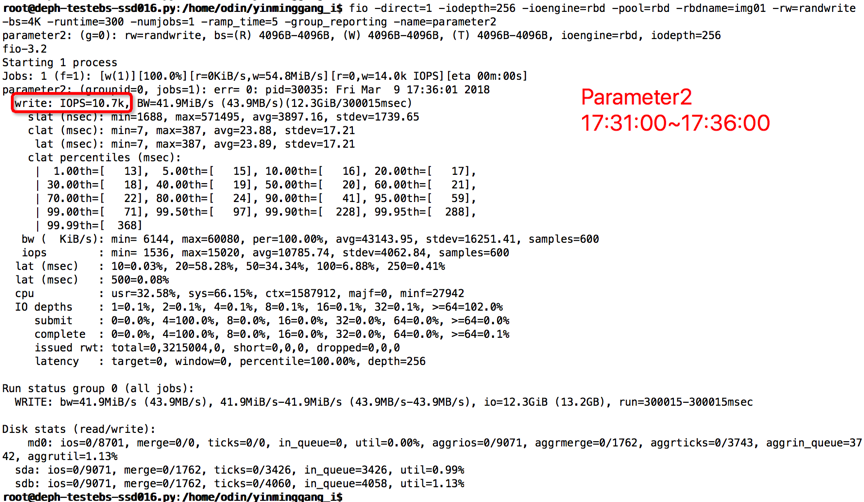
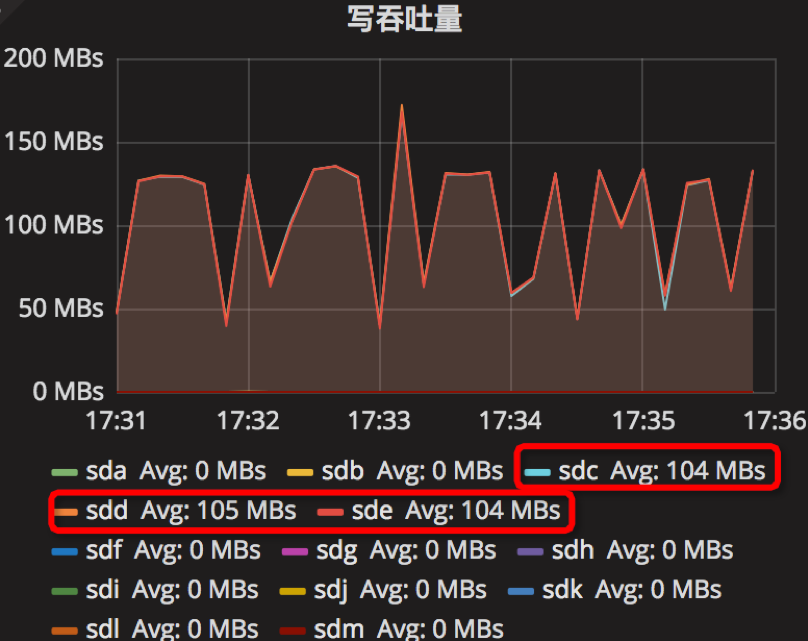
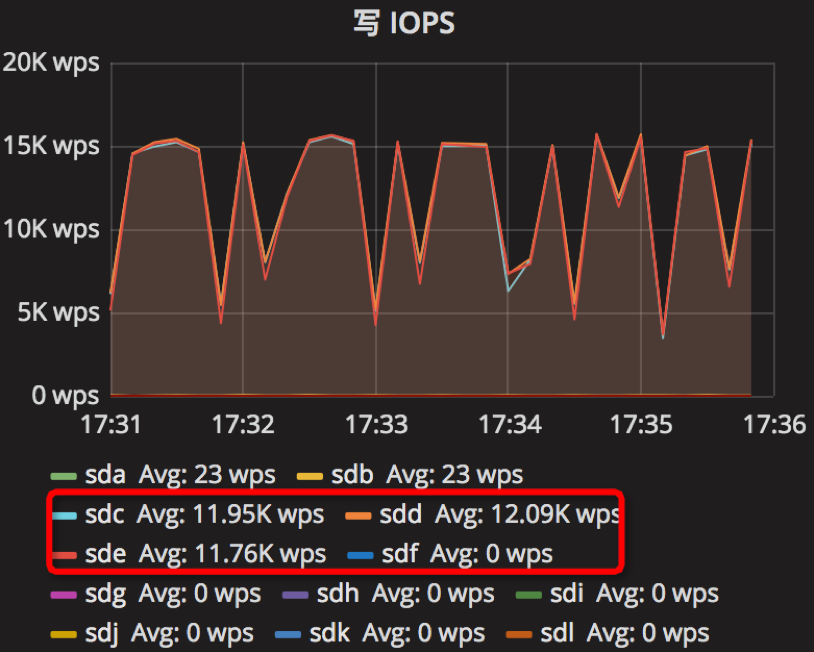
【Parameter2实验】
compression=kNoCompression
max_write_buffer_number=16
min_write_buffer_number_to_merge=8
recycle_log_file_num=4
write_buffer_size=1073741824
writable_file_max_buffer_size=2
compaction_readahead_size=8388608
时间段:17:31:00~17:36:00
结果如下


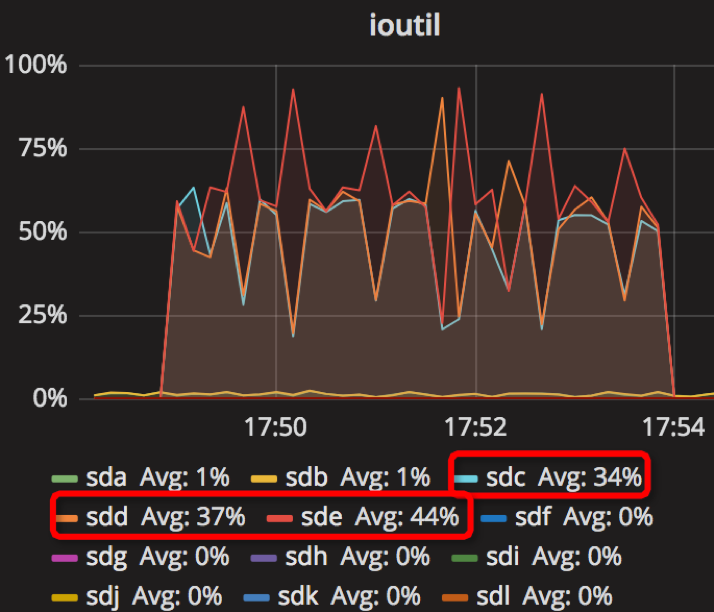
【Parameter3实验】
compression=kNoCompression
max_write_buffer_number=32
min_write_buffer_number_to_merge=16
recycle_log_file_num=4
write_buffer_size=2147483648
writable_file_max_buffer_size=4
compaction_readahead_size=16777216
时间段:17:49:01~17:54:01
结果如下

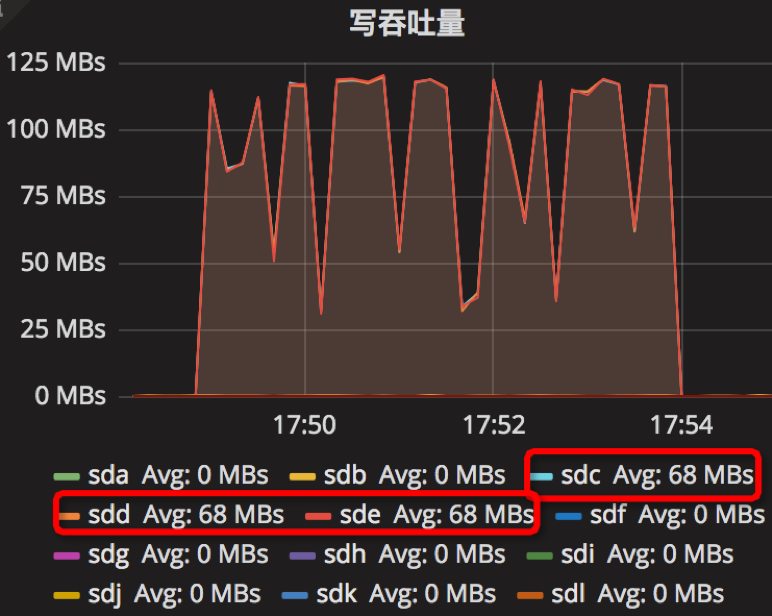
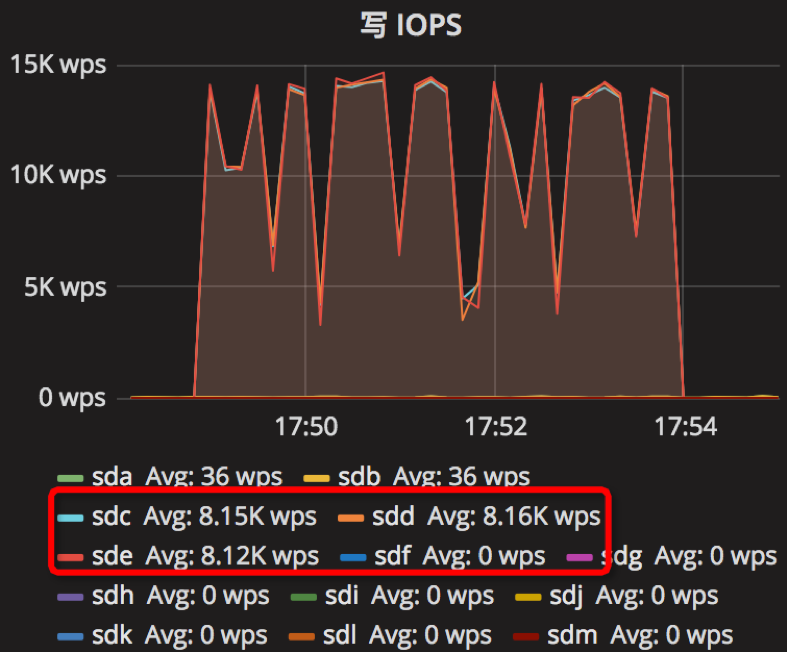
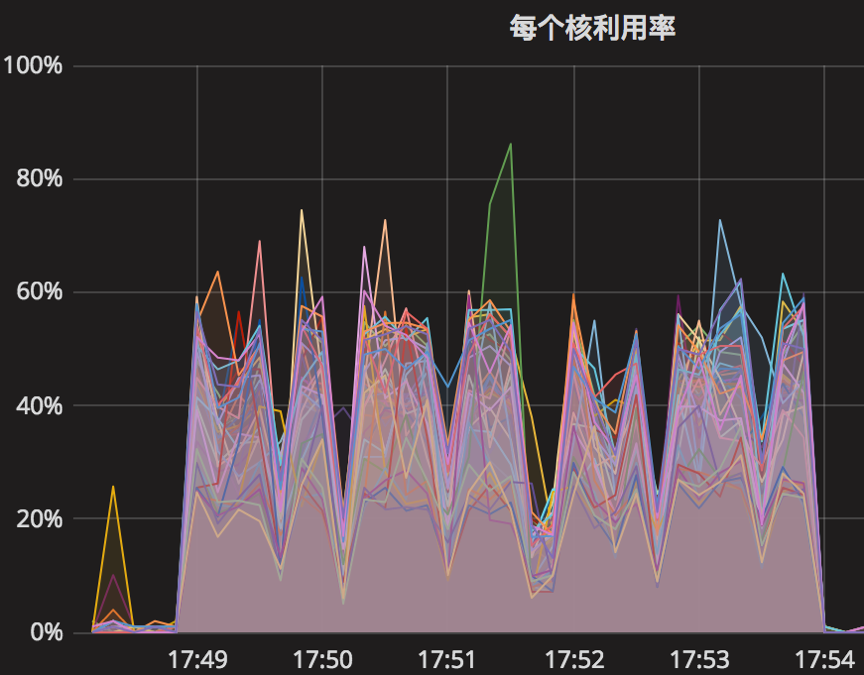
【Parameter4实验】
compression=kNoCompression
max_write_buffer_number=32
min_write_buffer_number_to_merge=16
write_buffer_size=2147483648
writable_file_max_buffer_size=4
compaction_readahead_size=16777216
【本实验暂没做】
【Parameter5实验】
compression=kNoCompression
max_write_buffer_number=64
min_write_buffer_number_to_merge=16
recycle_log_file_num=4
write_buffer_size=2147483648
writable_file_max_buffer_size=4
compaction_readahead_size= 33554432
时间段:10:34:01~10:39:01
结果如下



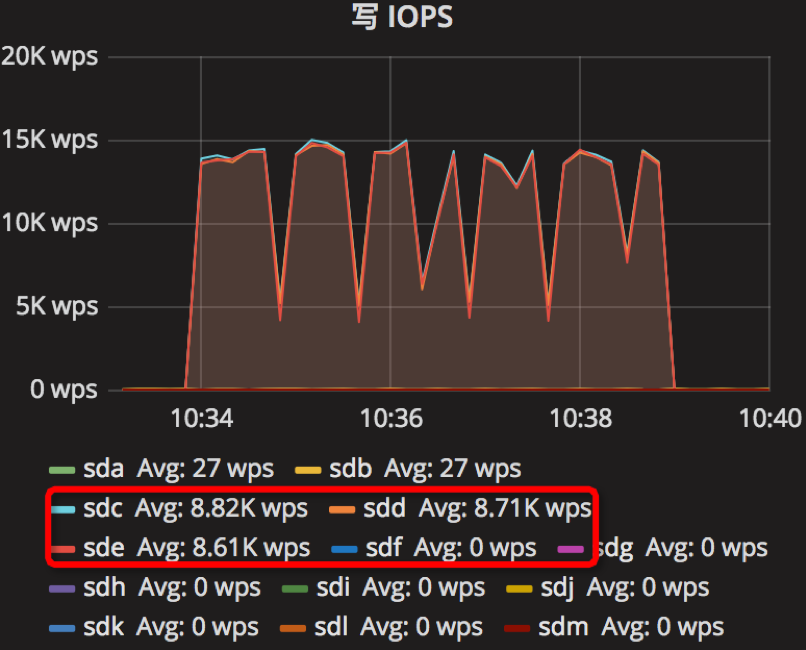

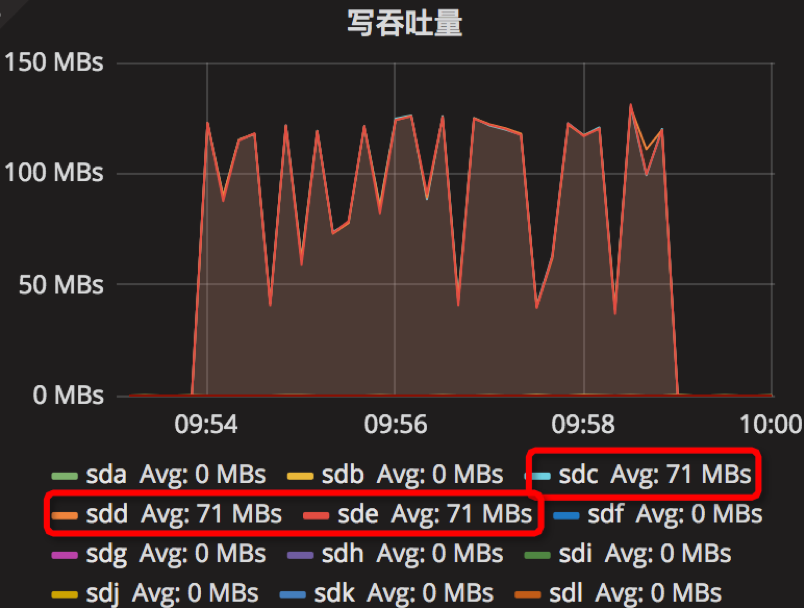
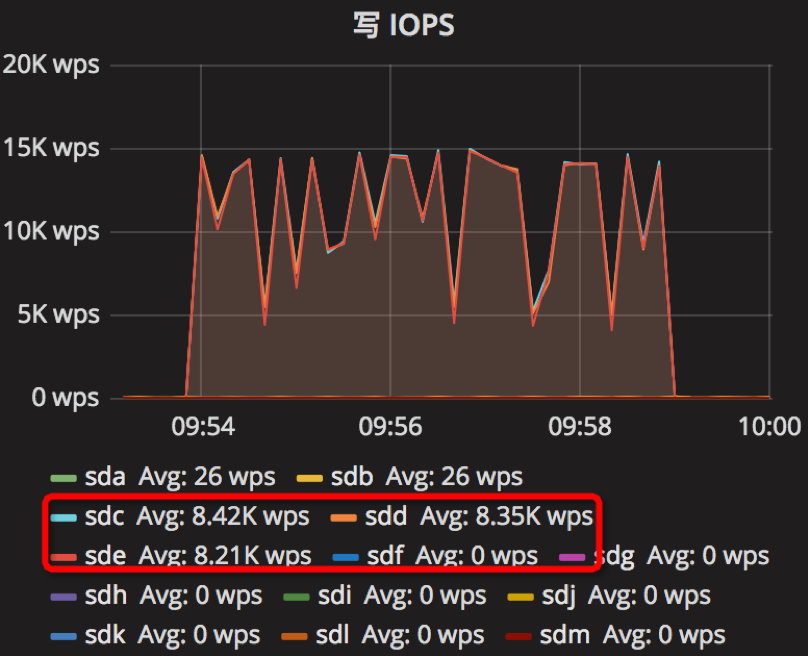
【Parameter6实验】
compression=kNoCompression
max_write_buffer_number=64
min_write_buffer_number_to_merge=8
recycle_log_file_num=4
write_buffer_size=2147483648
writable_file_max_buffer_size=8
compaction_readahead_size= 33554432
时间段:09:54:02~09:59:02
结果如下



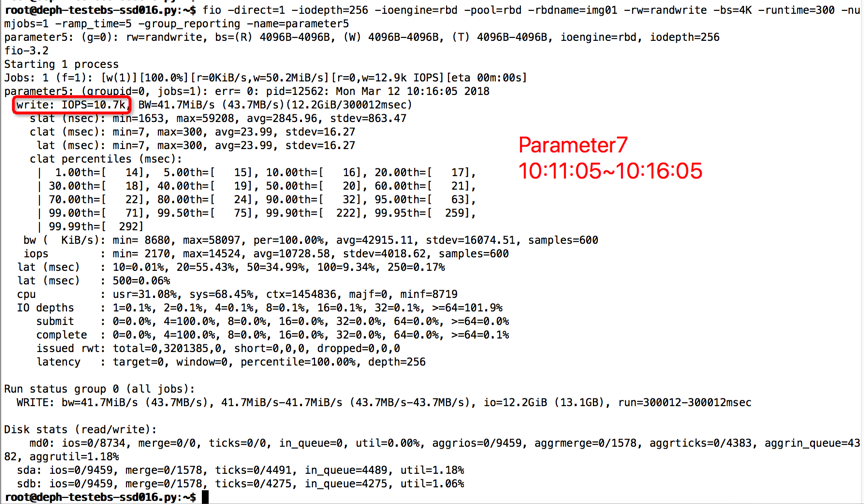
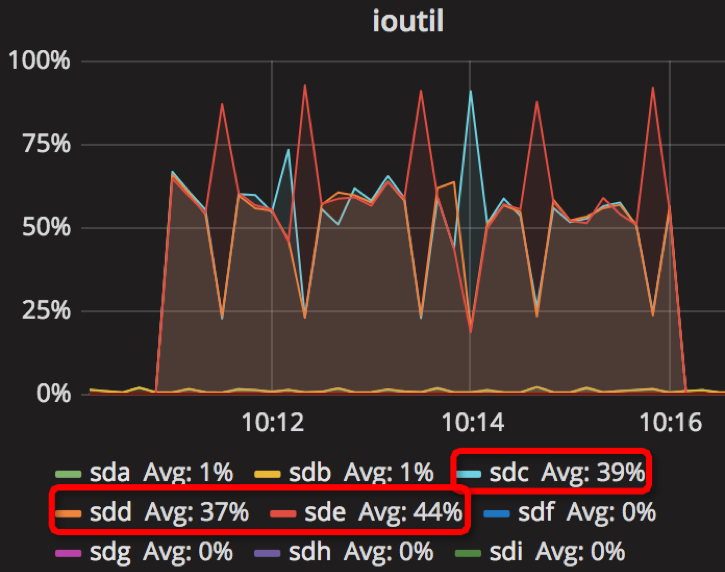
【Parameter7实验】
compression=kNoCompression
max_write_buffer_number=64
min_write_buffer_number_to_merge=16
recycle_log_file_num=4
write_buffer_size=2147483648
writable_file_max_buffer_size=4
compaction_readahead_size= 33554432
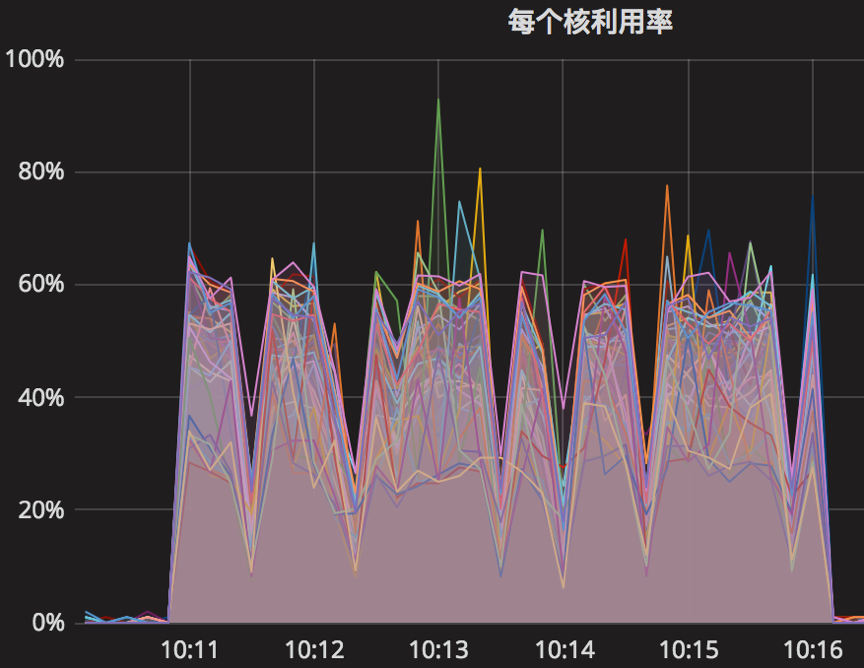
时间段:10:11:05~10:16:05
结果如下


【Parameter8实验】
compression=kNoCompression
max_write_buffer_number=256
min_write_buffer_number_to_merge=64
recycle_log_file_num=16
write_buffer_size=8589934592
writable_file_max_buffer_size=16
compaction_readahead_size= 134217728
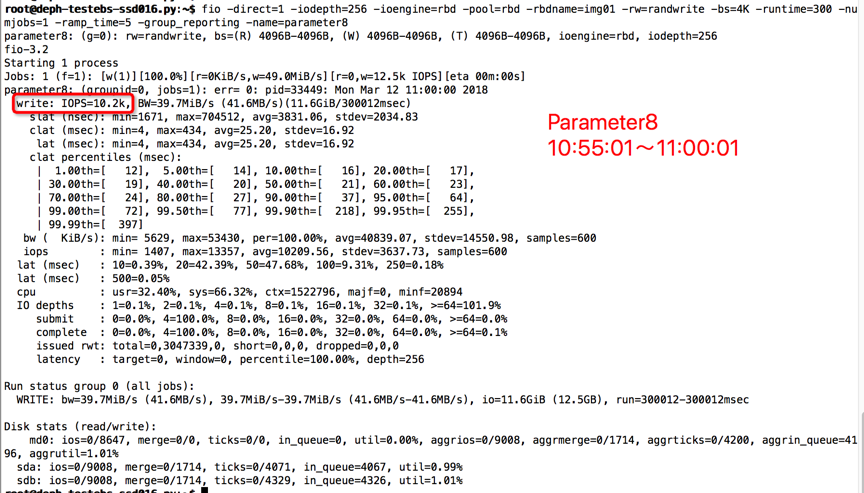
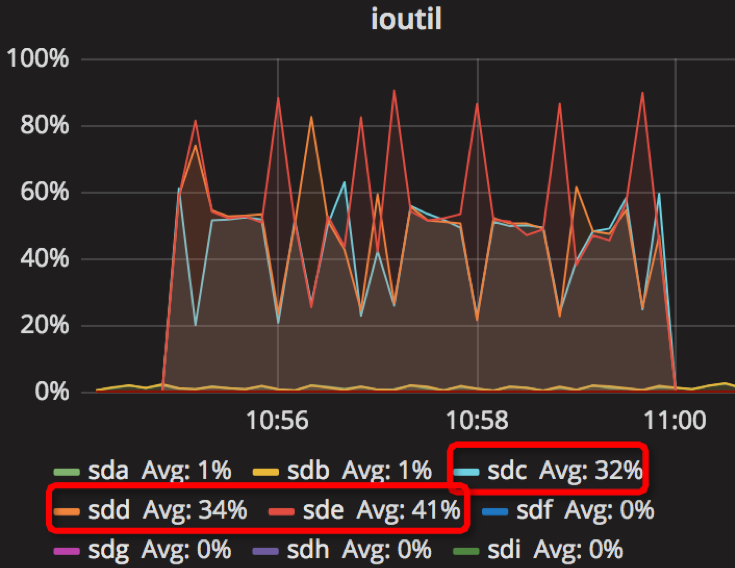
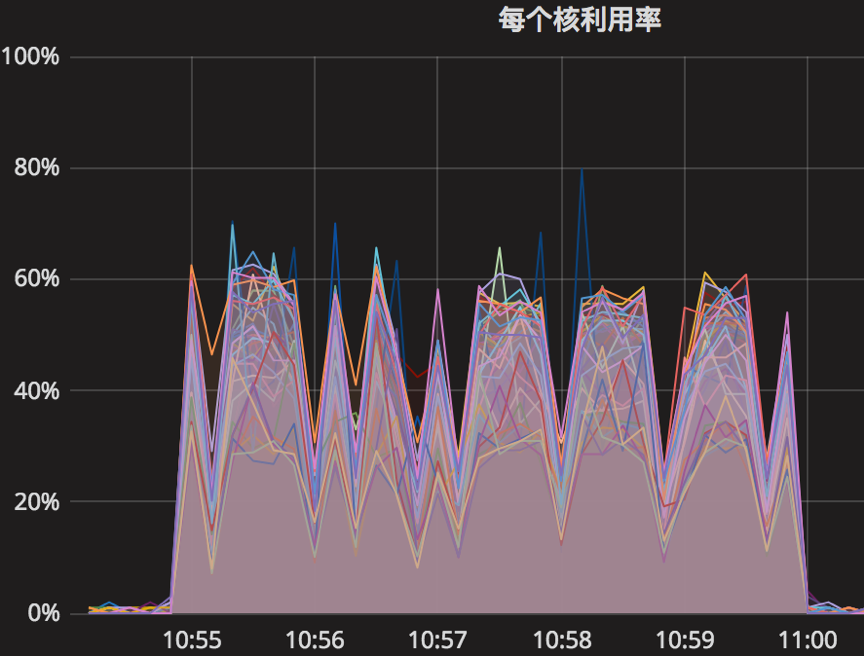
时间段:10:55:01~11:00:01
结果如下


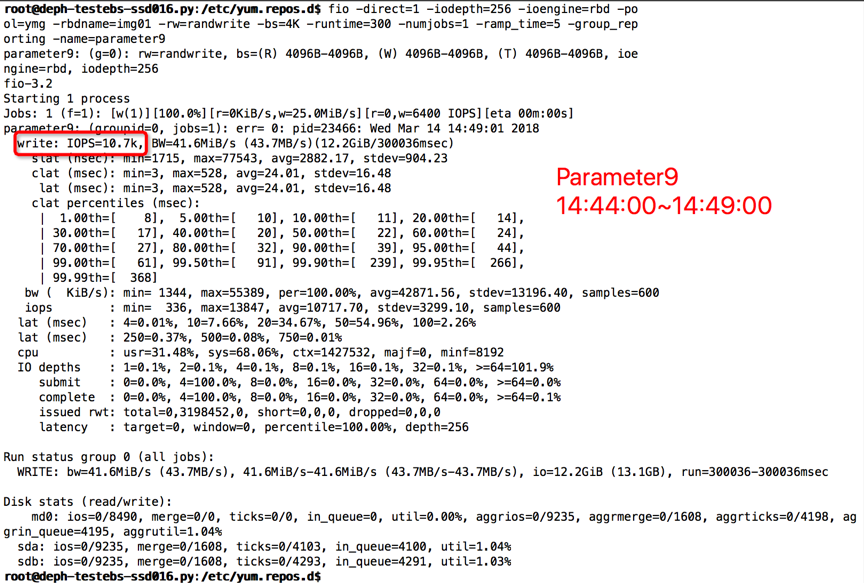
【Parameter9实验】
compression=kNoCompression
max_write_buffer_number=256
min_write_buffer_number_to_merge=4
recycle_log_file_num=16
write_buffer_size=1073741824
writable_file_max_buffer_size=134217728
compaction_readahead_size= 134217728
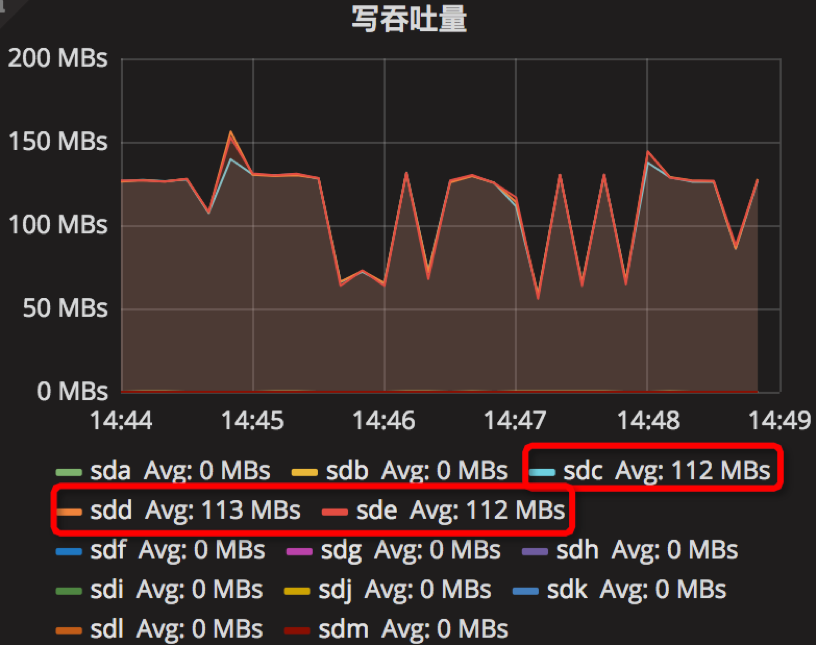
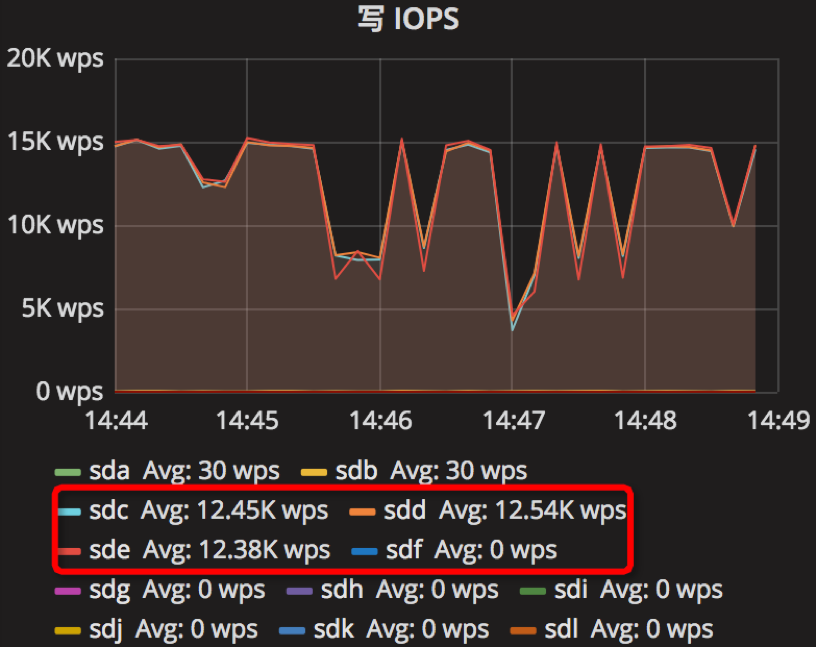
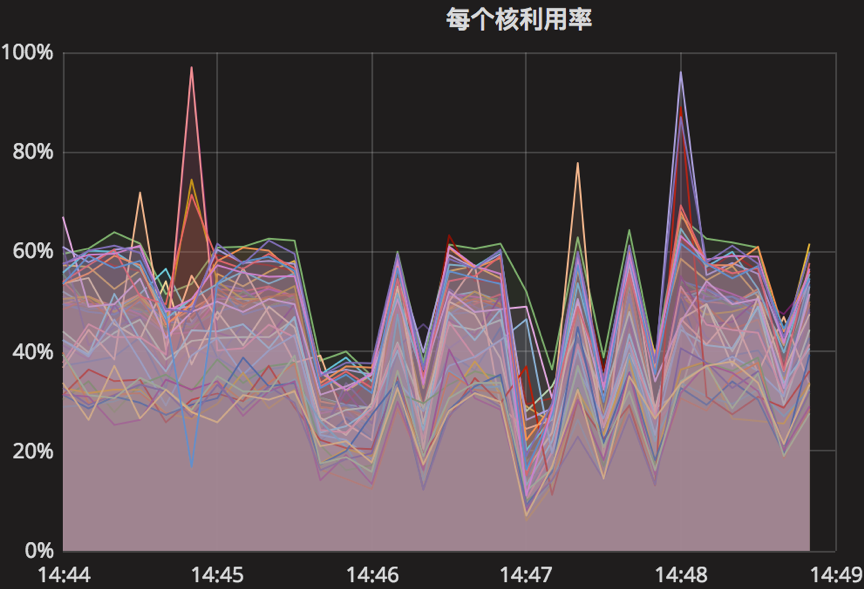
时间段:14:44:00~14:49:00
结果如下

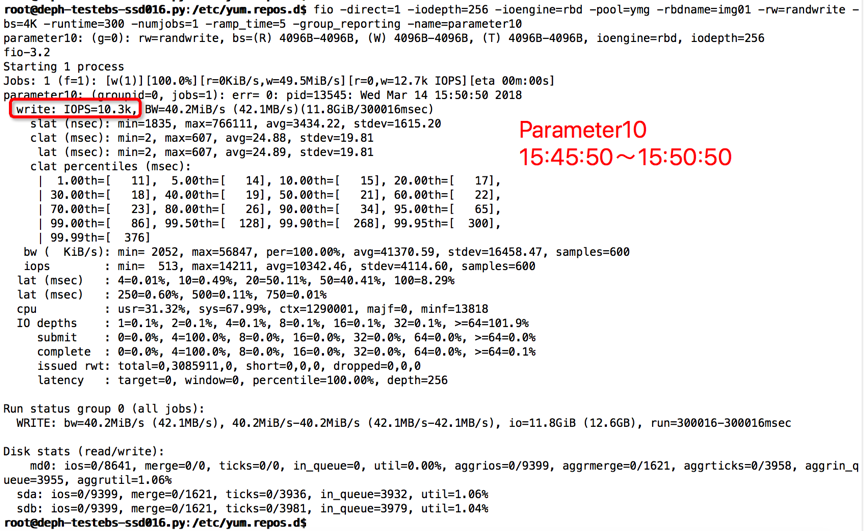
【Parameter10实验】
compression=kNoCompression
max_write_buffer_number=256
min_write_buffer_number_to_merge=2
write_buffer_size=536870912
writable_file_max_buffer_size=32768
compaction_readahead_size=32768
时间段:15:45:50~15:50:50
结果如下
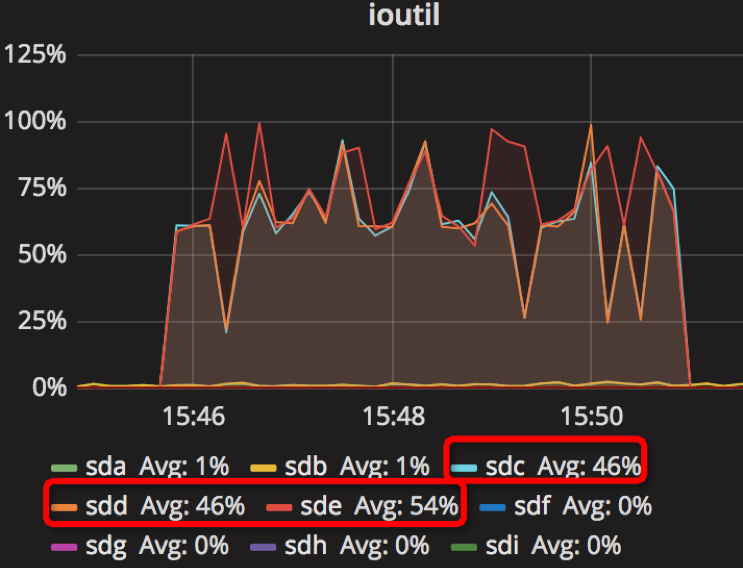

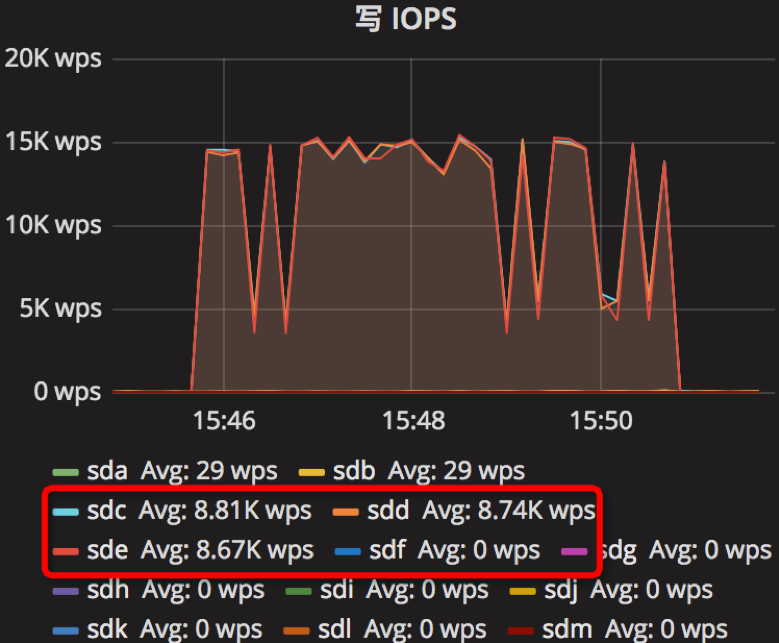
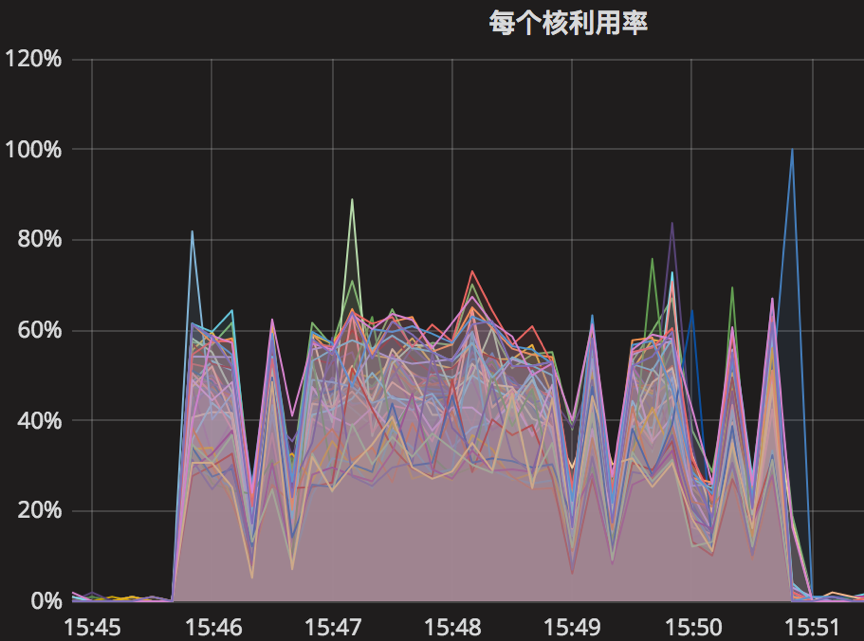
总结
根据上面的10组实验结果,我们实验的参数调节是参照一些文章,如我们进行了总结,发现机器的写速度约为40MB/s,让我们以parameter10实验为例,假如我们write_buffer_size=536870912(2^29),也即是64MB,也即是每1.6s产生一个新的memtable;min_write_buffer_number_to_merge=2,也就是每产生2个memtable,就进行合并操作,即每3.2s;根据max_write_buffer_number=256意思,我们应该尽量设置大一些;而参数writable_file_max_buffer_size和compaction_readahead_size应该设置差不多大小。其实parameter9和parameter10是个对比。参考
我们将结果进行了统计,详见xlsx文件
由结果可以知道,我们的调参是有效的,其中第9组实验结果表现较好,当然,优化还是要持续不断。