本文通过调节bluestore的参数来测试其4k-randwrite性能,主要是用fio工具来测试IOPS性能,以及相关内部监控系统来获取其他评价指标,如:osd写吞吐量,CPU利用率等等。调节的参数有:集群osd个数,image个数,bluestore_shard_finishers参数,osd_op_num_shards参数等。
任务一 cpu瓶颈测试
为确定cpu负载的影响,可降低osd数,如只采用3个osd构成三副本,在cpu不是瓶颈的情况下,测试性能相对硬件性能情况
1.1 环境搭建
由于题主环境是12-osd,所以需要卸载删除一些osd来达到3-osd,操作也简单。
登录ddy-ebs-admin.py机器
$ cd /data/apps/easysa/
$ ansible-playbook -i environments/ebs-py-test2/hosts playbooks/shrink-osd.yml -e osd_to_kill=3,4,5,6,7,8,9,10,11
登录服务器主机看集群情况,可以对比集群前后变化。
注:基于以前的集群环境,有可能集群这时会不正常($ceph -s),或许是以前pool导致的。可能需要删除掉以前的pool($ ceph osd pool delete ymg);并新建合适的pool($ceph osd pool create 3-osd-pool),以及新建image($seq 1 30 | xargs I {} rbd create 3-osd-pool/img{} –size 20G);最后还要填充它们
集群可能出现这个提醒,可以用($ceph osd pool application enable 3-osd-pool rbd)去掉
health: HEALTH_WARN
application not enabled on 1 pool(s)
1.2 实验设置
单客户端
实验1-1:4k随机写1个image
实验1-2:4k随机写8个image
实验1-3:4k随机写15个image
实验1-4:4k随机写30个image
双客户端
实验2-1:2-client各自随机写10个不同image
实验2-2:2-client各自随机写20个不同image
实验2-3:2-client各自随机写30个不同image
实验2-4:2-client各自随机写45个不同image
实验2-5:2-client各自随机写60个不同image
1.3 实验结果
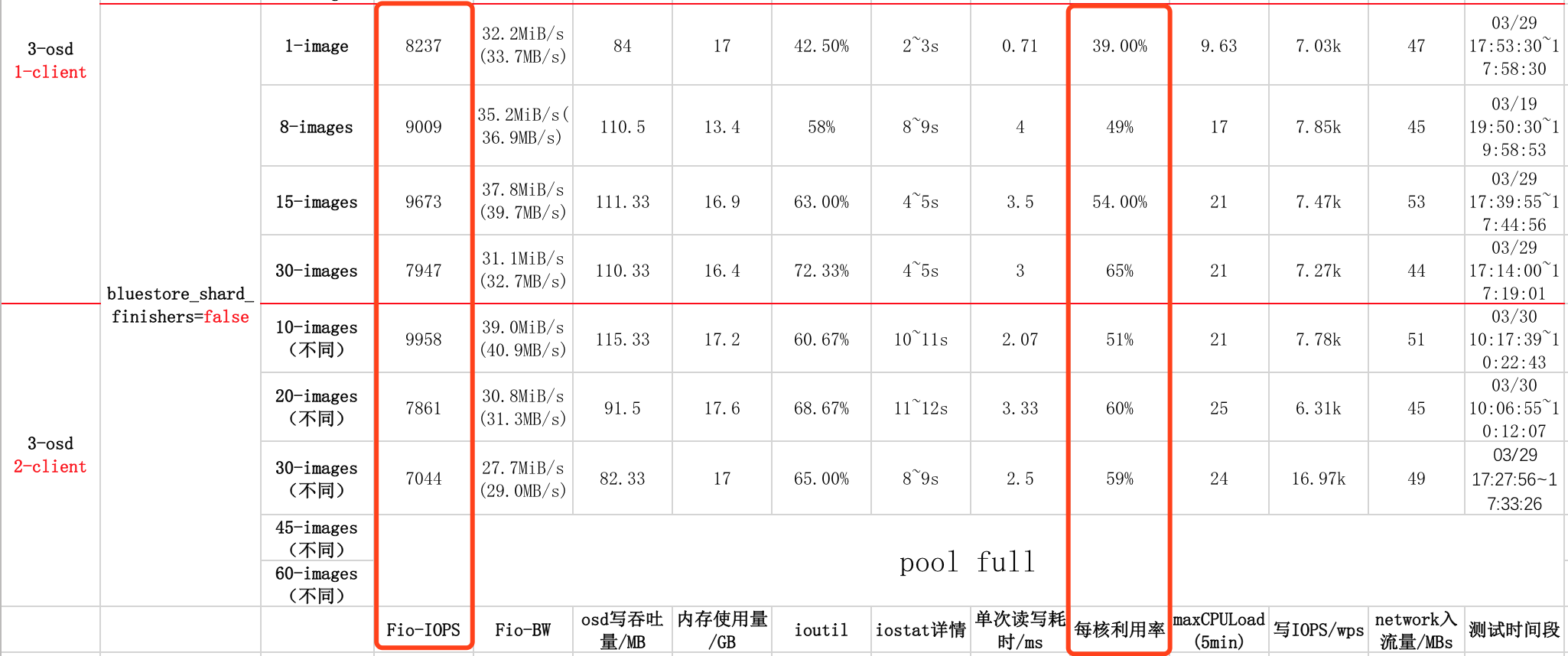
1.4 结果分析及结论
由上图可以知道,在【每核利用率】列,可以知道,此时集群没有达到CPU瓶颈,这是符合我们测试的要求;
在【Fio-IOPS】列,可以看出各组实验IOPS有一定的差距,但也没有太高IOPS,也没有太低IOPS,相差最大的为20%左右(1-client)和40%左右(2-client)。
但各组实验的IOPS都不高,可见osd数量是集群性能的一个重要因素。
任务二 librbd 瓶颈测试
对于一个volume iops只有两万多的问题,为确定是否是客户端的瓶颈,可以通过将同一个volume挂到多个节点,并发读写,测试总iops,因为对后端,多个客户端读写没有区别
2.1 环境搭建
配置搭建集群:1-server(deph-testebs-ssd015.py);2-client(deph-testebs-ssd013.py、deph-testebs-ssd016.py)
并挂载12-osds
2.2 实验设置
实验1-1:两个客户端并发4k随机写同一个image的相同位置(offset)(分区相同)bluestore_shard_finishers=false
两个客户端fio配置文件如下:


实验1-2:两个客户端并发4k随机写同一个image的不同位置(offset)(分区不同)bluestore_shard_finishers=false
两个客户端fio配置文件如下(创建image 时,每个image设置的为20G):


参照任务四,再加了下面两组实验:
实验2-1:两个客户端并发4k随机写同一个image的相同位置(offset)(分区相同)bluestore_shard_finishers=true
实验2-2:两个客户端并发4k随机写同一个image的不同位置(offset)(分区不同)bluestore_shard_finishers=true
2.3 实验结果

2.4 结果分析与结论
(1)可以看出2-client并发写单个image,其IOPS比1-client随机写IOPS要低很多。
(2)对于2-client并发写相同image的不同分区,其IOPS相差不大。
(3)bluestore_shard_finishers参数对本次实验结果影响不大。
综上所述,多客户端并发写1-image的IOPS性能不如单客户端随机写性能。
任务三 finisher线程性能影响
默认bluestore finisher为单线程,调整bluestore_shard_finishers为true,对比iops差别
3.1 环境搭建
在基于任务二环境(12-osd)基础上,完成以下实验:
deph-testebs-ssd015.py:$vim /etc/ceph/ceph.conf
添加:bluestore_shard_finishers=true
重启osd集群
deph-testebs-ssd015.py:$systemctl restart ceph-osd@*.service
查看参数值(随意选取几个osd查看即可)
deph-testebs-ssd015.py:$ceph daemon osd.0 config show|grep bluestore_shard_finishers
3.2 实验设置
总共有12组实验:
(1)bluestore_shard_finishers=true
实验1-1:2-client各自写30个完全不同的images
实验1-2:2-client各自写45个完全不同的images
实验1-3:2-client各自写60个完全不同的images
实验1-4:2-client并发写30个相同的images
实验1-5:2-client并发写45个相同的images
实验1-6:2-client并发写60个相同的images
(2)bluestore_shard_finishers=false(默认)
实验2-1:2-client各自写30个完全不同的images
实验2-2:2-client各自写45个完全不同的images
实验2-3:2-client各自写60个完全不同的images
实验2-4:2-client并发写30个相同的images
实验2-5:2-client并发写45个相同的images
实验2-6:2-client并发写60个相同的images
3.3 实验结果

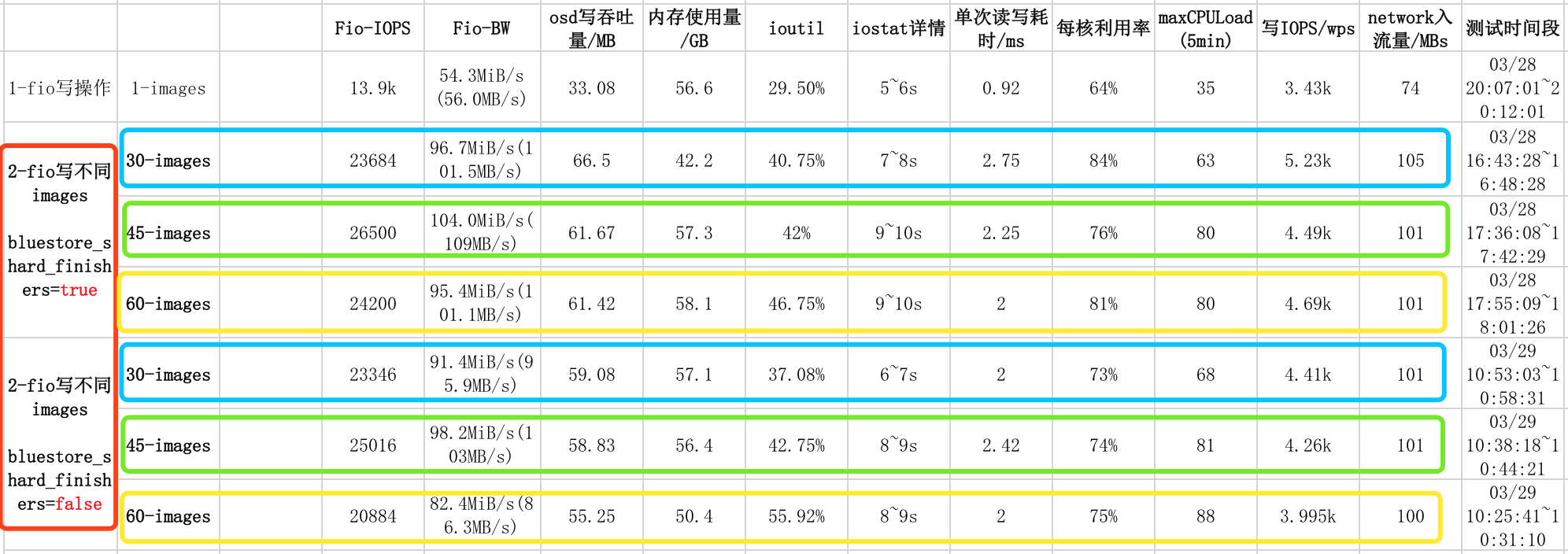
3.4 结果分析与总结
可以看的出,随着image的数量增加,bluestore_shard_finishers参数的影响正在变得明显(IOPS增长率在持续增加),如下表所示:
| 2-client写不同image | image数 | IOPS增长率 | 2-client写相同image | image数 | IOPS增长率 |
| 30 | 1.45% | 30 | 7.31% | ||
| 45 | 5.93% | 45 | 3.93% | ||
| 60 | 15.88% | 60 | 9.51% |
不论俩客户端是写相同或不同image,image=30,45,60过程中,bluestore_shard_finishers=true的IOPS性能都要更优。而且image=60时,IOPS性能提升的更明显(近15%和10%)。
综上所述,bluestore_shard_finishers=true,对多客户端下的多image随机写性能有积极促进作用。
3.5 附加实验
在基于任务一环境(3-osd)基础上,添加实验环境为1-client情况下,参数bluestore_shard_finishers的影响
共8组附加实验
(1)bluestore_shard_finishers=true
实验3-1:1-client随机写1个image
实验3-2:1-client随机写8个image
实验3-3:1-client随机写15个image
实验3-4:1-client随机写30个image
(2)bluestore_shard_finishers=false(默认)
实验4-1:1-client随机写1个image
实验4-2:1-client随机写8个image
实验4-3:1-client随机写15个image
实验4-4:1-client随机写30个image
实验结果
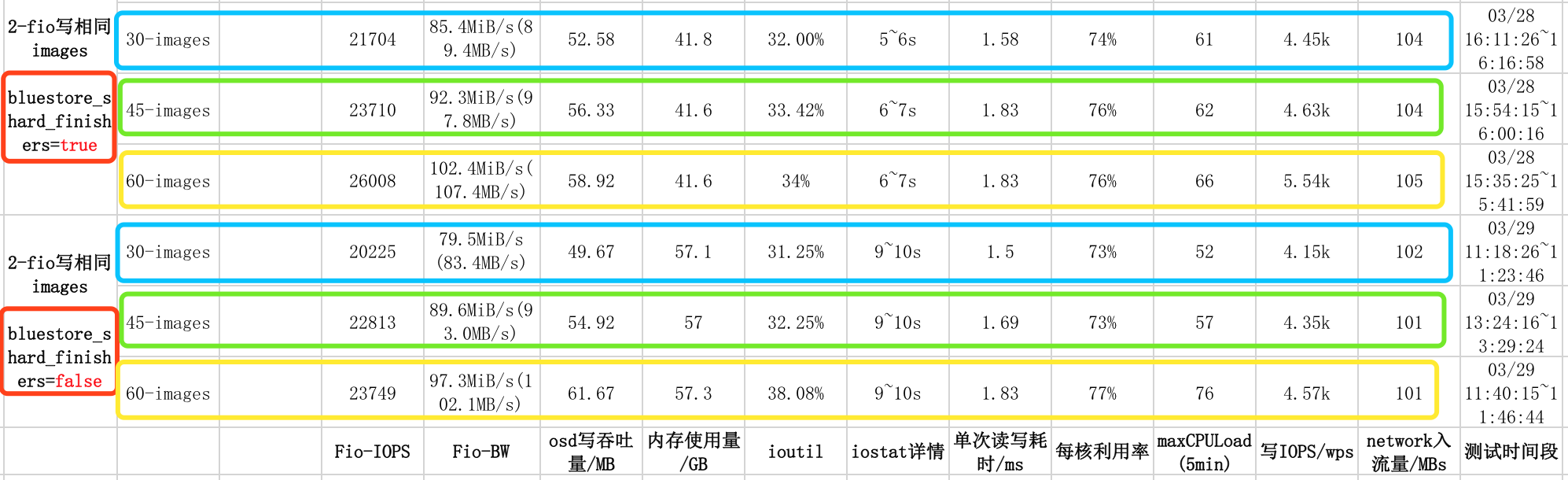
3.6 结果分析及结论
可以看的出,随着image的数量增加,bluestore_shard_finishers参数对IOPS性能影响越来越大,也越来越好(IOPS增长率在持续增加),如下表所示:
| image数 | IOPS增长率 |
| 1 | -7.64% |
| 8 | 11.00% |
| 15 | 12.68% |
| 30 | 22.60% |
综上可得,bluestore_shard_finishers参数对单客户端下多image随机写操作性能有促进作用。
任务四 测试osd_op_num_shards参数的影响
调节osd_op_num_shards参数值,对比IOPS变化
4.1 环境搭建
在基于任务一基础上的环境(3-osd),来完成该任务
默认osd_op_num_shards=0,

root@deph-testebs-ssd015.py:/etc/ceph$ vim ceph.conf
osd_op_num_shards=4
4.2 osd_op_num_shards参数分析
阅读ceph源码,查看osd_op_num_shards参数的计算源码,如下所示(主要看第二幅图):
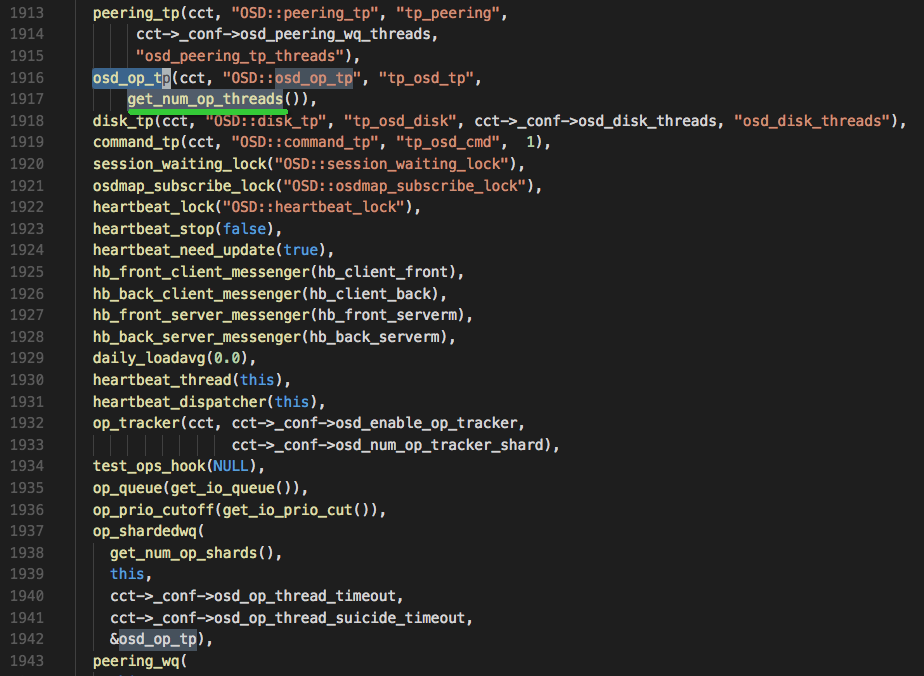
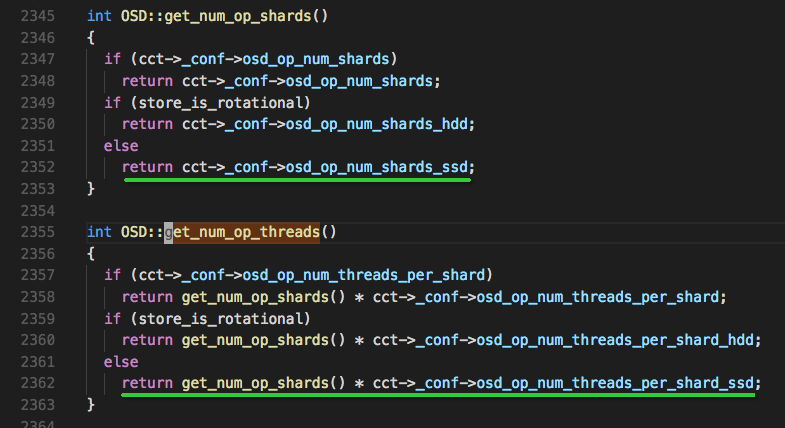
源码中有两个函数,get_num_op_shards()和get_num_op_threads(),是分别求OSD::op_shardedwq中存储io的队列个数及OSD::op_shardedwq中总的io分发线程数
总线程数=队列数*每个队列线程数
可看出,当osd_op_num_shards为true时,返回osd_op_num_shards的值;否则就看返回osd_op_num_shards_hhd或osd_op_num_shards_ssd的值,源码中store_is_rotational是bool类型,表示设备属性(默认是true也即是hhd)。
而求线程数函数get_num_op_threads(),同理也是以变量osd_op_num_threads_per_shard和store_is_rotational来决定用哪个公式。
(1)默认情况下,查看相关参数值:

可看到osd_op_num_shards=0和osd_op_num_threads_per_shard=0,所以计算线程总数公式=osd_op_num_shards_ssd*osd_op_num_threads_per_shard_ssd=8*2=16
(2)通过ceph.conf文件设置参数osd_op_num_shards=2,重启集群

通过上面分析,因此总线程数=osd_op_num_shards*osd_op_num_threads_per_shard_ssd=2*2=4
- 测试
在客户端运行fio的4k-randwrite操作,同时在服务端多次运行 top -H -p $pid -n 1 | grep tp_osd_tp ,计算有多少个线程,如下:

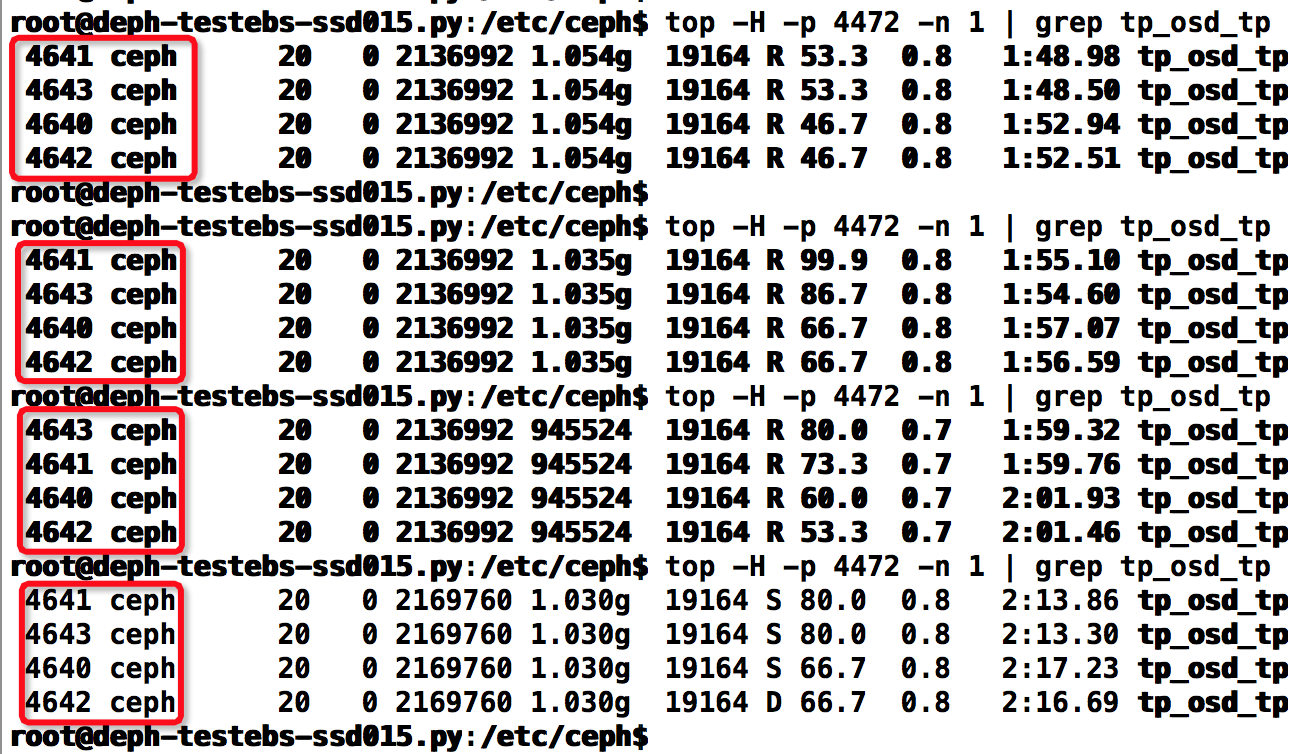
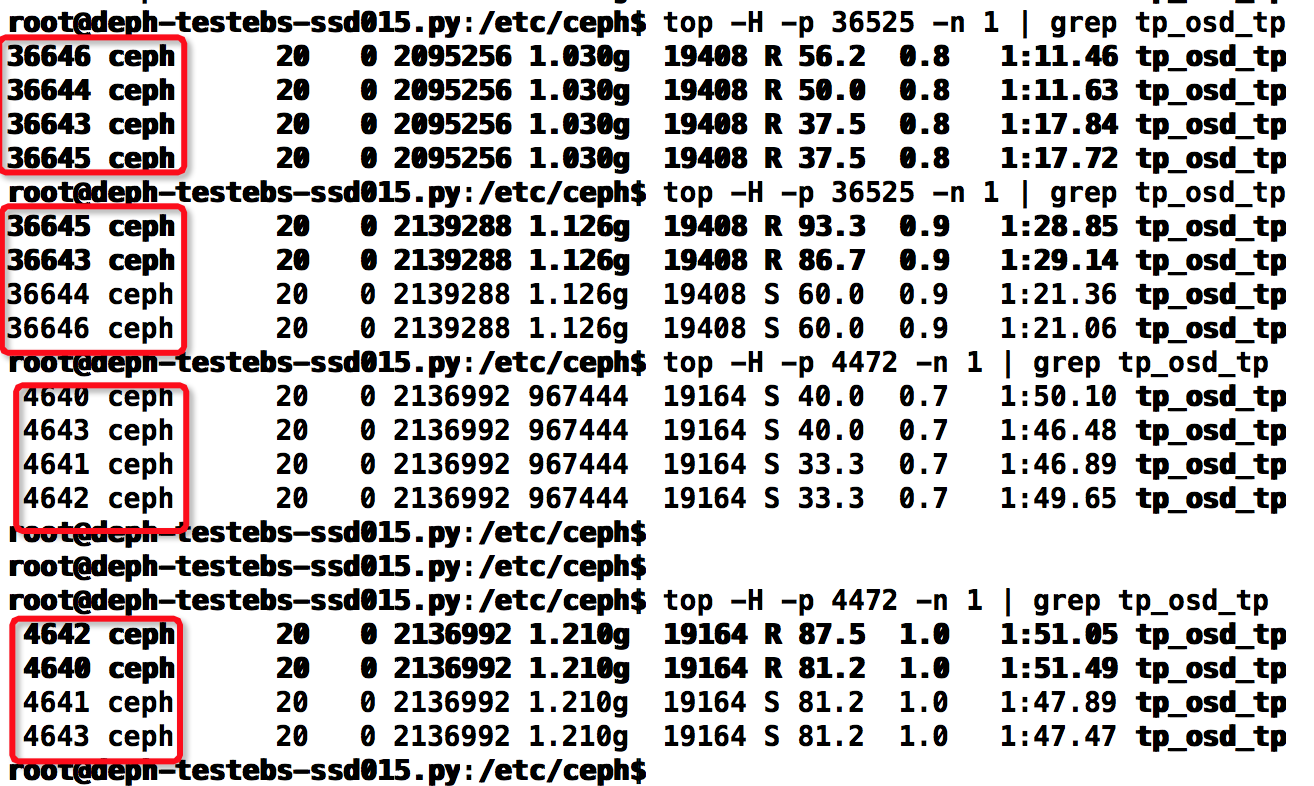
看得出一直都是4个线程。故我们的计算方式是正确的。下面来看真正的实验吧。
4.3 实验设置
共20组实验
(1)osd_op_num_shards=0(默认),即总线程数=8*2=16
实验1-1:1-client随机写1个image
实验1-2:1-client随机写8个image
实验1-3:1-client随机写15个image
实验1-4:1-client随机写30个image
(2)osd_op_num_shards=2,即总线程数=2*2=4
实验2-1:1-client随机写1个image
实验2-2:1-client随机写8个image
实验2-3:1-client随机写15个image
实验2-4:1-client随机写30个image
(3)osd_op_num_shards=4,即总线程数=4*2=8
实验3-1:1-client随机写1个image
实验3-2:1-client随机写8个image
实验3-3:1-client随机写15个image
实验3-4:1-client随机写30个image
(4)osd_op_num_shards=8,即总线程数=8*2=16
实验4-1:1-client随机写1个image
实验4-2:1-client随机写8个image
实验4-3:1-client随机写15个image
实验4-4:1-client随机写30个image
(5)osd_op_num_shards=16,即总线程数=16*2=32
实验5-1:1-client随机写1个image
实验5-2:1-client随机写8个image
实验5-3:1-client随机写15个image
实验5-4:1-client随机写30个image4.4 实验结果
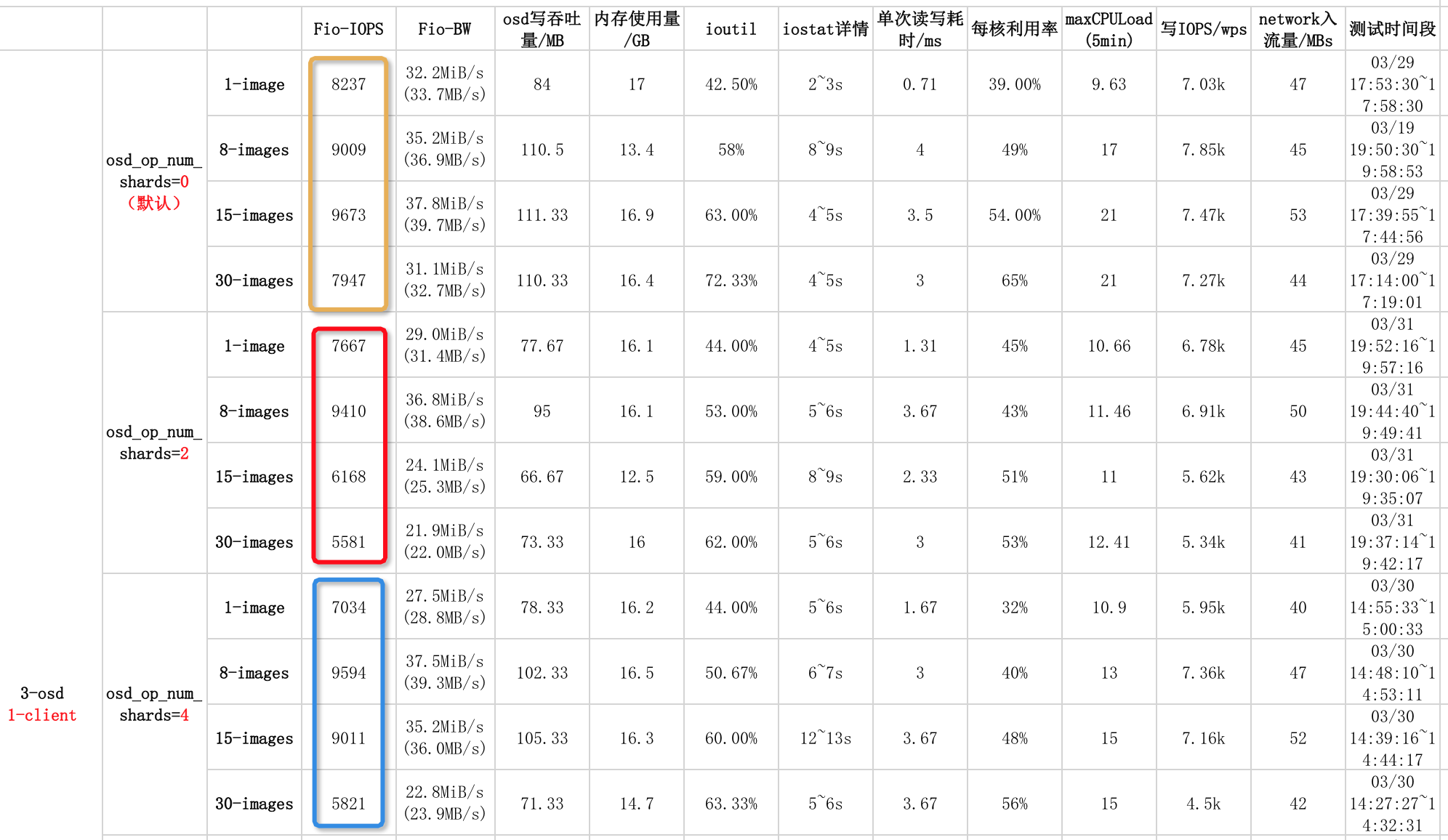
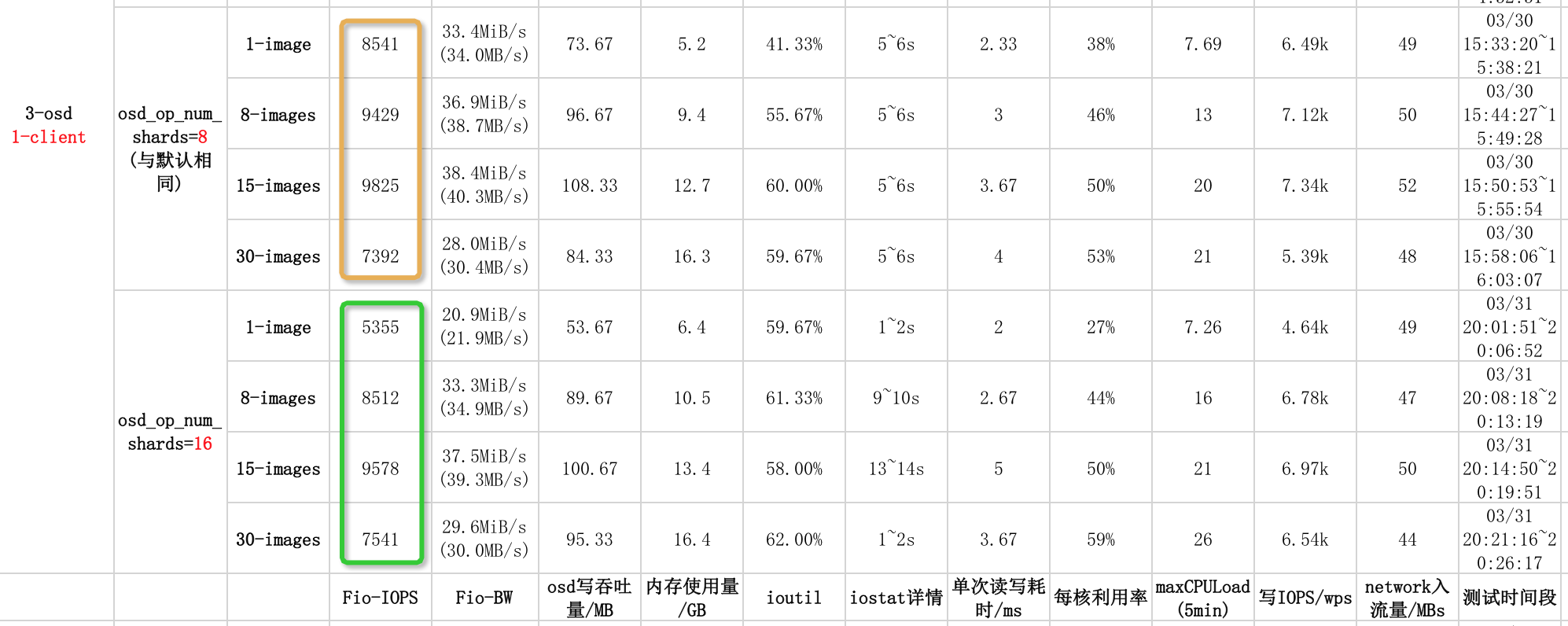
4.5 结果分析及总结
由上图可以看出,五组实验的各四小组实验结果的IOPS都相差不大,参数osd_op_num_shards效果不明显。
(1)当1-image时,5组实验中,osd_op_num_shards默认参数的IOPS最高,性能最好。
(2)当8-image时,各组实验都不差,默认参数第二高,表示调参没起到效果。
(3)当15-image时,默认参数IOPS最高,性能最好。
(4)当30-image时,默认参数IOPS最高,性能最好。
综上所述,参数osd_op_num_shards对集群IOPS性能影响不明显。
实验结果源文件下载