gdbprof,是一款基于系统时间(而非cpu事件)的性能分析工具,它通过sampling的方式进行性能统计的。每隔period(默认为0.1秒),给gdb发送sigint信号,然后循环每个thread,根据该thread的call trace,统计函数的调用情况。 它是基于python实现的,中间用到了gdb的python api。
gdbprof源码 本文采用的gdbprof优化版本 本人forked版本,随时欢迎。
实验环境
搭建ceph-osd集群(本文用了3个osd.0、osd.1、osd.2)
服务端:server_host(osd)
客户端:client_host(mons、mgrs)
服务端需安装gdb,客户端需安装fio(都自行解决),下载gdbprof
实验过程
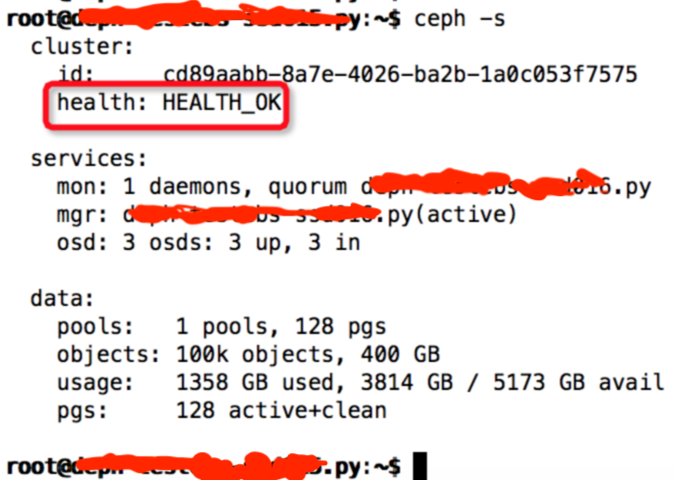
(1)简单查看下集群是否正常:
$ceph osd tree

$ceph -s
(2)查看所有osd对应进程及进程号
$ps aux|grep ceph-osd

实验一 求解耗系统资源的线程(单image和10-images)
客户端(server_host)操作:
(1)fio 创建pool(或默认rbd)和image,并进行后续操作
$ rbd create –pool ymg –image img01 –size 40G
(2)先进行填充实验
$fio -direct=1 -iodepth=256 -ioengine=rbd -pool=rbd -rbdname=img01 -rw=write -bs=1M -size=40G -ramp_time=5 -group_reporting -name=full-fill
(3)再进行4k-randWrite的单image操作
$ fio -direct=1 -iodepth=256 -ioengine=rbd -pool=rbd -rbdname=img01 -rw=randwrite -bs=4K -runtime=300 -numjobs=1 -ramp_time=5 -group_reporting -name=one_gdbprof
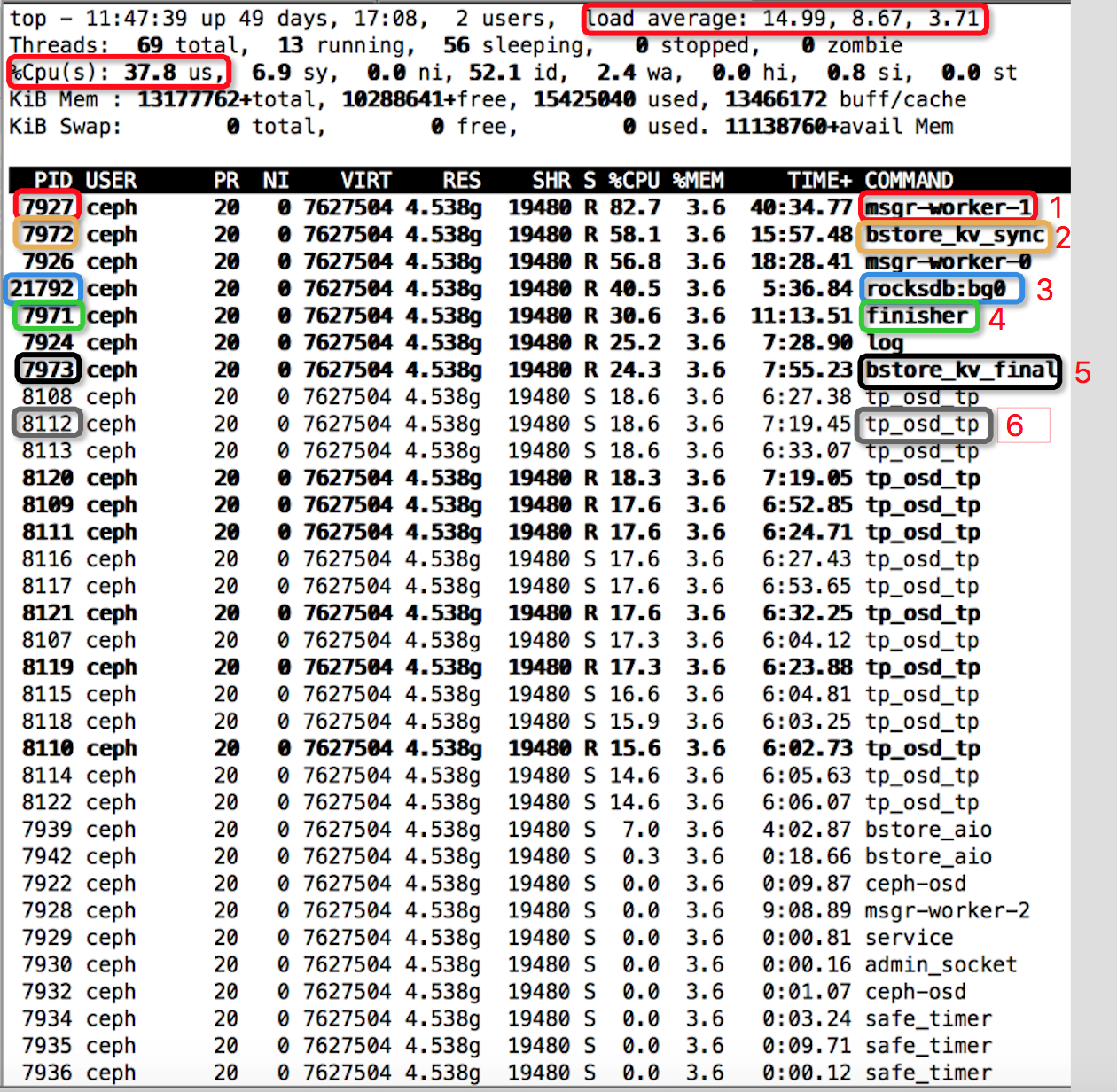
(4)与此同时,服务端机器(client_host)需要并行执行top命令
$top -p 7922 -H
也即追踪进程7922(随意选一个)在过程中的所有线程对资源消耗情况,结果如下所示:
对比实验:10个images的4k-randWrite的实验操作:
$ BS=4k RW=randwrite fio images.fio
得先创建10个images
$rbd create ymg/img00 -s 40G
images.fio内容如下所示:
[global]
direct=1
ioengine=rbd
pool=ymg
bs=${BS}
size=40G
time_based
runtime=500
ramp_time=5
iodepth=256
rw=${RW}
group_reporting
[00]
rbdname=img00
[01]
rbdname=img01
[02]
rbdname=img02
[03]
rbdname=img03
[04]
rbdname=img04
[05]
rbdname=img05
[06]
rbdname=img06
[07]
rbdname=img07
[08]
rbdname=img08
[09]
rbdname=img09
服务端执行 $top -p 7922 -H
结果如下所示
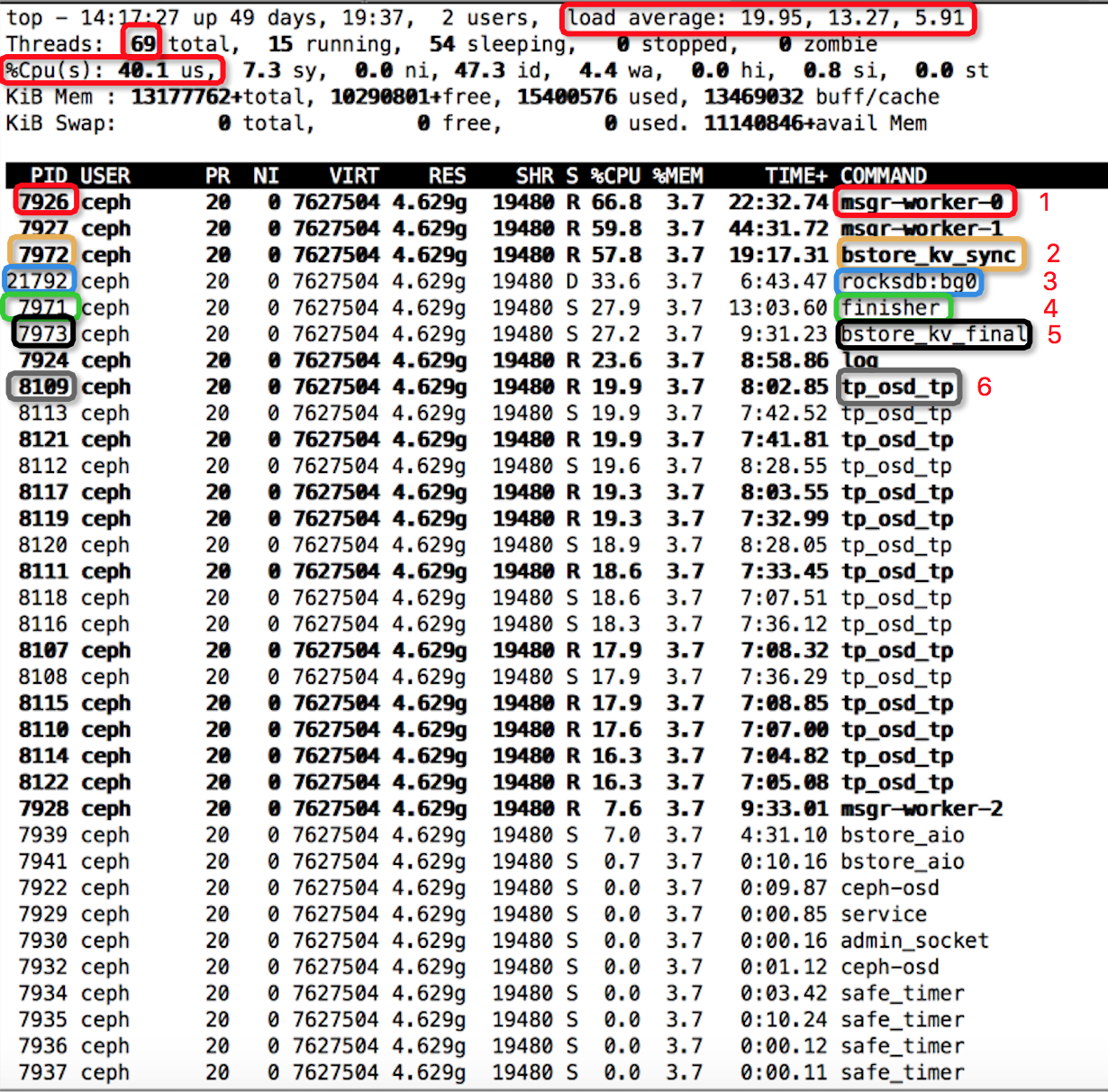
总结
由上面的一对儿实验可知:4k-randwrite过程中,比较消耗资源的线程有:msgr-worker-0(7926)/msgr-worker-1(7927)、bstore_kv_sync(7972)、rocksdb::bg0(21792)、finisher(7971)、bstore_kv_final(7973)、log(7924)、tp_osd_tp(8109)
接下来,我们需要具体看这些线程中具体哪些函数最消耗时间。这就是gdbprof的亮相了。
实验二 求解耗系统资源的具体函数(单image)
在客户端进行4k-randWrite操作同时(fio命令),服务端要跑gdbprof工具(可下面参考原文中的.docx文件),切换到gdbprof目录,有gdbprof.py
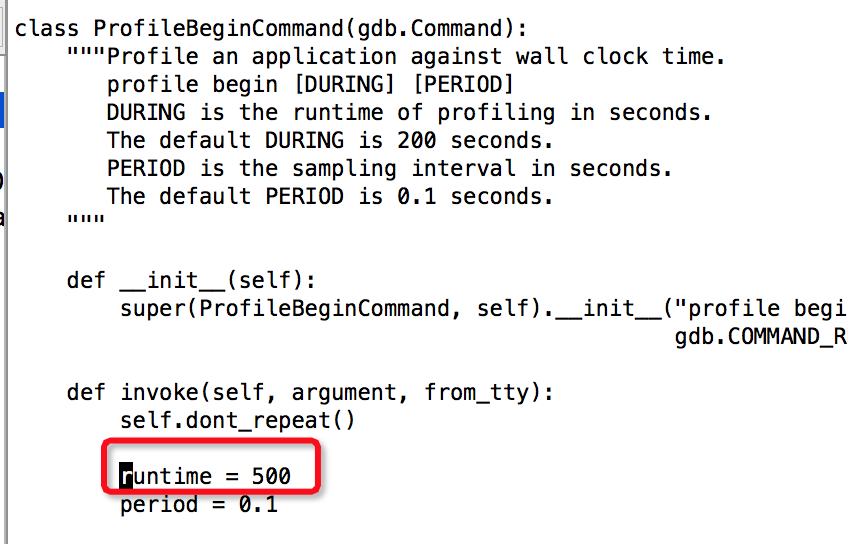
$vim gdbprof.py
line140,调节采样运行时间(无需太短或长),据说单位为秒,但感觉是采样次数,也就是样本个数,本人设过500,1000,2000,5000(等待时间太长),如下所示:
$sudo gdb -ex ‘set pagination off’ -ex ‘attach 7922’ -ex ‘source gdbprof.py’ -ex ‘profile begin’ -ex ‘quit’
注:在运行过程中,可能会出现一些下面的debuginfo信息
$yum install ceph-debuginfo.x86_64 –enablerepo didi_deph
运行结束后就可以看到打印出来的结果,共有69个线程的信息
先找出打印出的线程函数信息与上面线程的对应关系:
$gdb
(gdb) attach 7922
(gdb) info threads
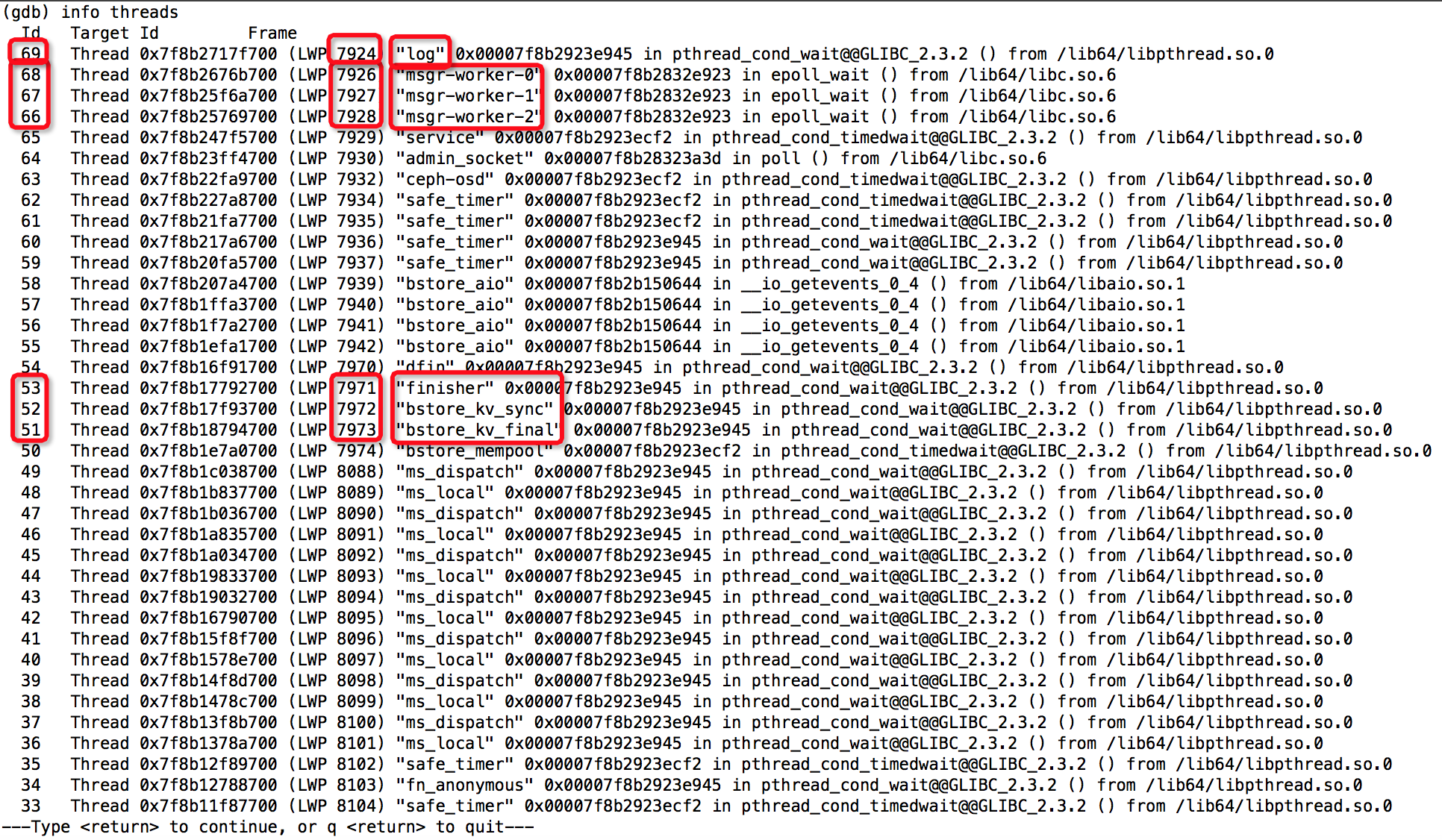
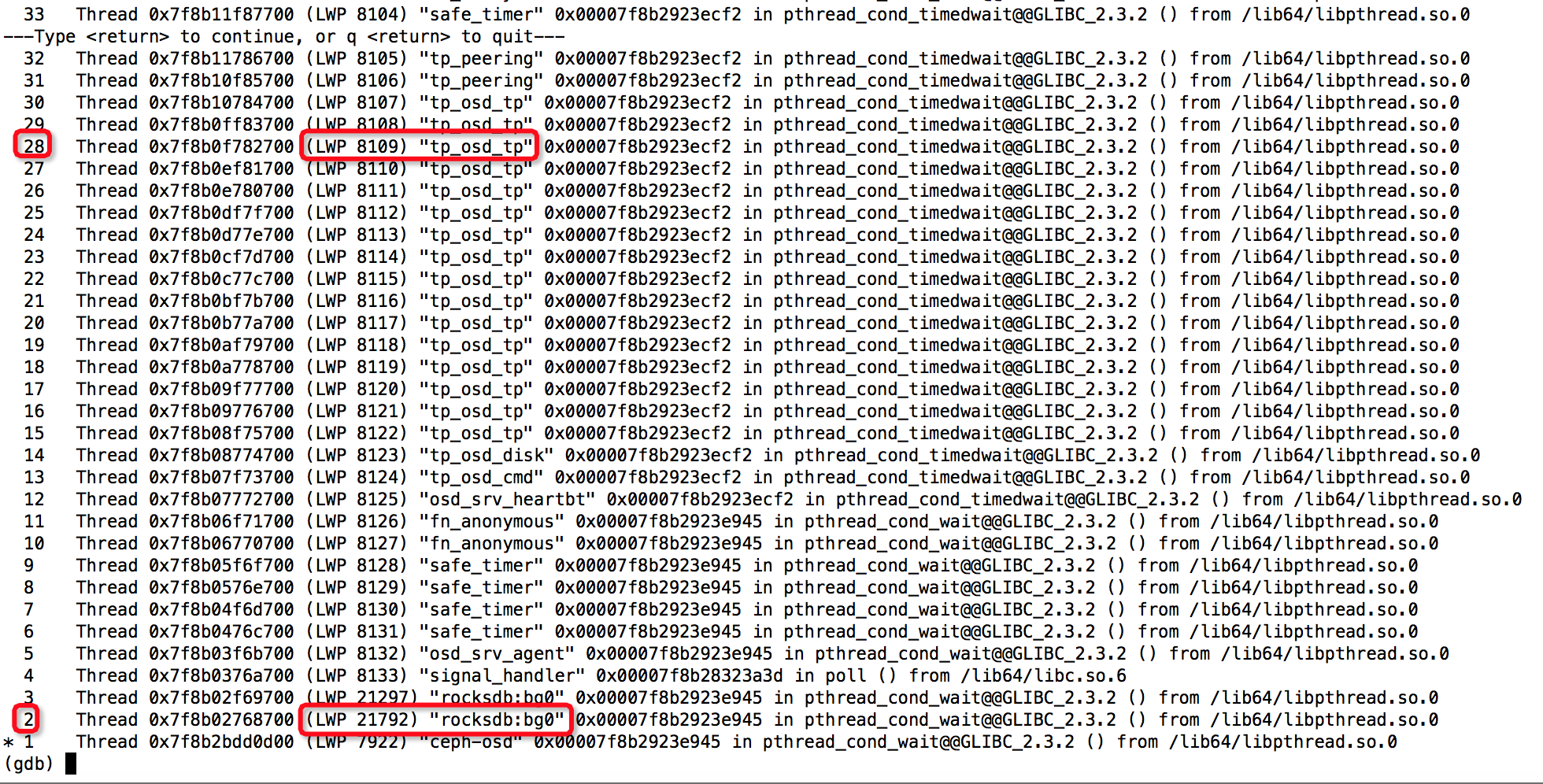
接着,贴出6个较为耗资源的线程的结果:Thread: 2===21792===rokcsdb::bg0、Thread: 28===8109===tp_osd_tp、Thread: 51===7973===bstore_kv_final、Thread: 52===7972===bstore_kv_sync、Thread: 53===7971===finisher、Thread: 68===7926===msgr_worker_0,可以看出哪些函数较为消耗资源,由于结果较长,部分如下所示:
Thread: 2===21792===rokcsdb::bg0
+ 100.00% clone
+ 100.00% start_thread
+ 100.00% None
+ 100.00% rocksdb::ThreadPoolImpl::Impl::BGThreadWrapper
+ 100.00% rocksdb::ThreadPoolImpl::Impl::BGThread
+ 69.00% rocksdb::DBImpl::BackgroundCallCompaction
| + 69.00% rocksdb::DBImpl::BackgroundCompaction
| + 69.00% rocksdb::CompactionJob::Run
| + 69.00% rocksdb::CompactionJob::ProcessKeyValueCompaction
| + 56.80% rocksdb::CompactionIterator::Next
| | + 42.20% rocksdb::MergingIterator::Next
| | | + 42.00% Next
| | | | + 25.00% b::(anonymous namespace)::TwoLevelIterator::Next
| | | | | + 25.00% Next
| | | | | + 24.40% b::(anonymous namespace)::TwoLevelIterator::SkipEmptyDataBlocksForward
| | | | | | + 24.40% b::(anonymous namespace)::TwoLevelIterator::InitDataBlock
| | | | | | + 24.20% rocksdb::BlockBasedTable::BlockEntryIteratorState::NewSecondaryIterator
| | | | | | | + 24.20% rocksdb::BlockBasedTable::NewDataBlockIterator
| | | | | | | + 23.60% b::(anonymous namespace)::ReadBlockFromFile
| | | | | | | | + 23.40% rocksdb::ReadBlockContents
| | | | | | | | | + 23.40% ReadBlock
| | | | | | | | | + 22.40% rocksdb::RandomAccessFileReader::Read
| | | | | | | | | | + 22.40% b::(anonymous namespace)::ReadaheadRandomAccessFile::Read
| | | | | | | | | | + 22.40% ReadIntoBuffer
| | | | | | | | | | + 22.40% BlueRocksRandomAccessFile::Read
| | | | | | | | | | + 22.40% read_random
| | | | | | | | | | + 22.40% BlueFS::_read_random
| | | | | | | | | | + 22.40% KernelDevice::read_random
| | | | | | | | | | + 22.40% pread
| | | | | | | | | | + 22.40% pread64
| | | | | | | | | + 1.00% Value
| | | | | | | | | + 1.00% b::crc32c::ExtendImpl<rocksdb::crc32c::Fast_CRC32>
| | | | | | | | | + 1.00% Fast_CRC32
| | | | | | | | | + 1.00% Slow_CRC32
| | | | | | | | + 0.20% rocksdb::Block::Block(rocksdb::BlockContents&&, unsigned long, unsigned long, rocksdb::Statistics*)
| | | | | | | | + 0.20% BlockContents
| | | | | | | | + 0.20% operator=
| | | | | | | + 0.40% rocksdb::BlockBasedTable::MaybeLoadDataBlockToCache
| | | | | | | + 0.40% rocksdb::BlockBasedTable::GetDataBlockFromCache
| | | | | | | + 0.40% b::(anonymous namespace)::GetEntryFromCache
| | | | | | | + 0.40% rocksdb::ShardedCache::Lookup
| | | | | | | + 0.20% rocksdb::LRUCache::GetShard
| | | | | | + 0.20% b::(anonymous namespace)::TwoLevelIterator::SetSecondLevelIterator
| | | | | + 0.40% rocksdb::BlockIter::ParseNextKey
| | | | | | + 0.20% TrimAppend
| | | | | | | + 0.20% EnlargeBufferIfNeeded
| | | | | | | + 0.20% tc_newarray
| | | | | | + 0.20% DecodeEntry
| | | | | + 0.20% b::(anonymous namespace)::TwoLevelIterator::Next
| | | | | + 0.20% Next
| | | | + 17.00% b::(anonymous namespace)::TwoLevelIterator::SkipEmptyDataBlocksForward
| | | | + 17.00% b::(anonymous namespace)::TwoLevelIterator::InitDataBlock
| | | | + 17.00% rocksdb::BlockBasedTable::BlockEntryIteratorState::NewSecondaryIterator
| | | | + 17.00% rocksdb::BlockBasedTable::NewDataBlockIterator
| | | | + 16.80% b::(anonymous namespace)::ReadBlockFromFile
| | | | + 16.80% rocksdb::ReadBlockContents
| | | | + 16.80% ReadBlock
| | | | + 16.60% rocksdb::RandomAccessFileReader::Read
| | | | | + 16.60% b::(anonymous namespace)::ReadaheadRandomAccessFile::Read
| | | | | + 16.40% ReadIntoBuffer
| | | | | | + 16.40% BlueRocksRandomAccessFile::Read
| | | | | | + 16.40% read_random
| | | | | | + 16.40% BlueFS::_read_random
| | | | | | + 16.40% KernelDevice::read_random
| | | | | | + 16.40% pread
| | | | | | + 16.40% pread64
| | | | | + 0.20% TryReadFromCache
| | | | | + 0.20% memcpy
| | | | | + 0.20% __memcpy_ssse3_back
| | | | + 0.20% Value
| | | | + 0.20% b::crc32c::ExtendImpl<rocksdb::crc32c::Fast_CRC32>
| | | | + 0.20% Fast_CRC32
| | | | + 0.20% Slow_CRC32
| | | + 0.20% replace_top
| | | + 0.20% downheap
| | | + 0.20% operator()
| | + 14.60% rocksdb::CompactionIterator::NextFromInput
| | + 13.20% rocksdb::MergingIterator::Next
| | | + 12.80% Next
| | | | + 9.40% b::(anonymous namespace)::TwoLevelIterator::Next
| | | | | + 9.40% Next
| | | | | + 9.20% b::(anonymous namespace)::TwoLevelIterator::SkipEmptyDataBlocksForward
| | | | | | + 9.20% b::(anonymous namespace)::TwoLevelIterator::InitDataBlock
......
......
......
Thread: 28===8109===tp_osd_tp
......
......
......
具体文件可下载
由上面结果可以知道6个线程中哪些函数较为消耗资源,如下所示:
(1)Thread: 2===21792===rokcsdb::bg0:
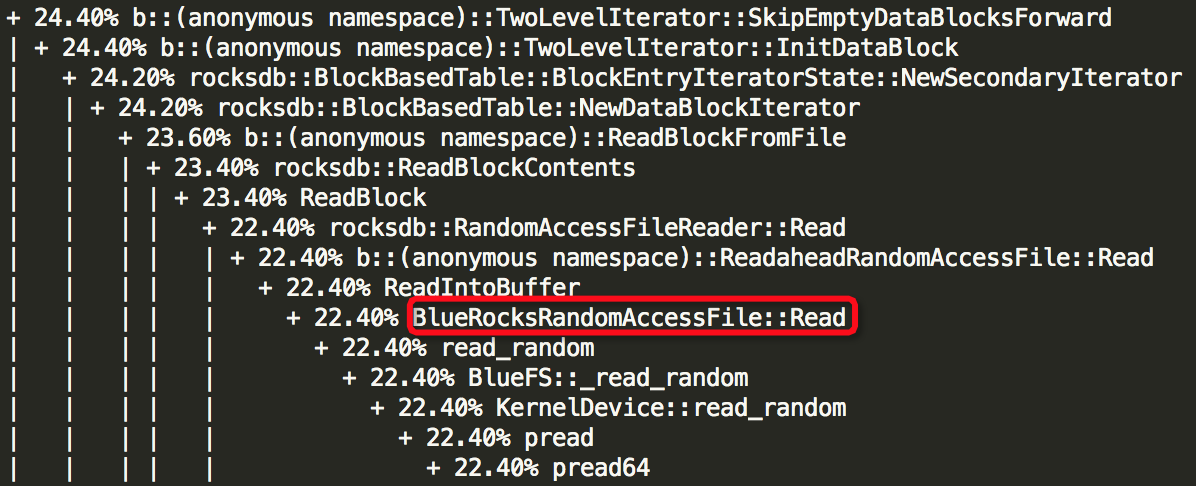
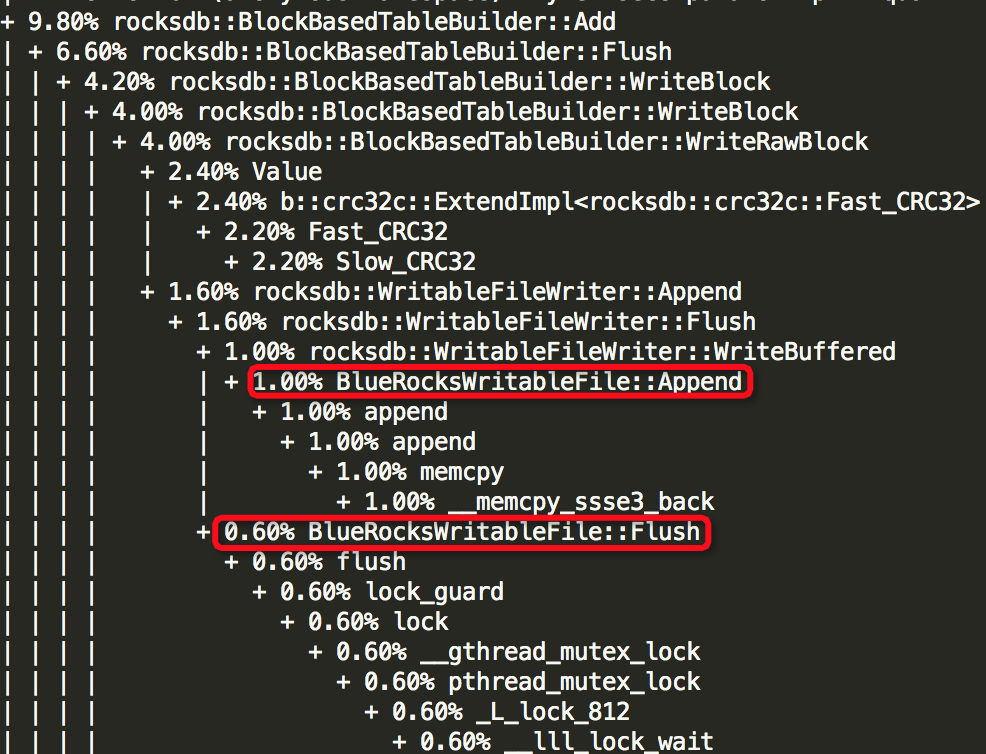
(2)Thread: 28===8109===tp_osd_tp:
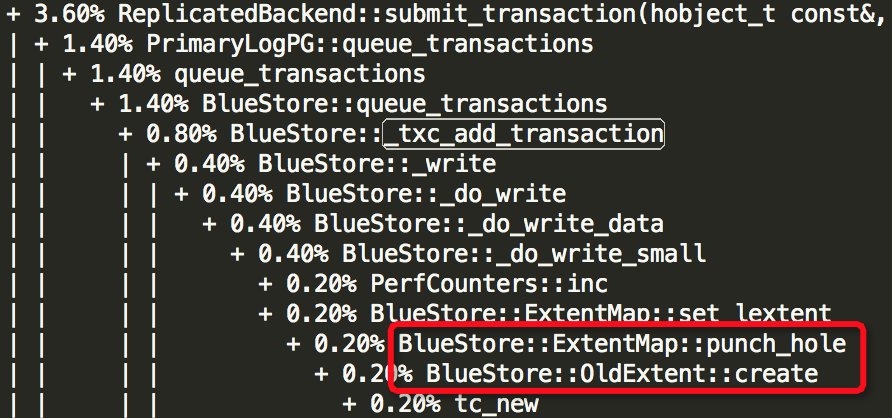
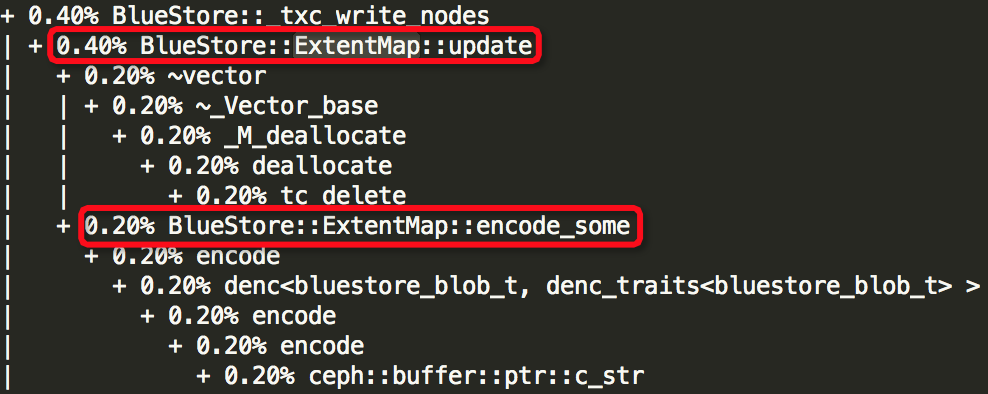
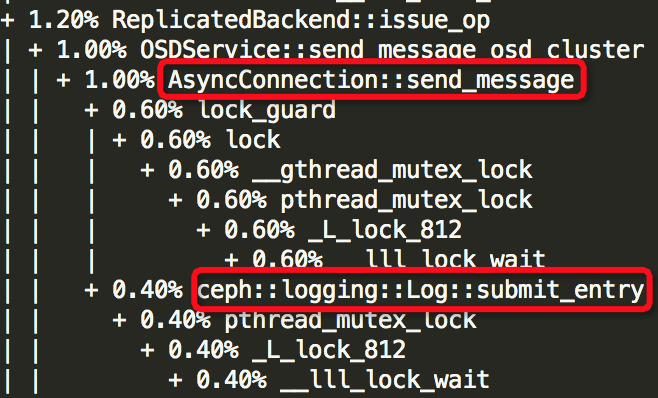
(3)Thread: 51===7973===bstore_kv_final
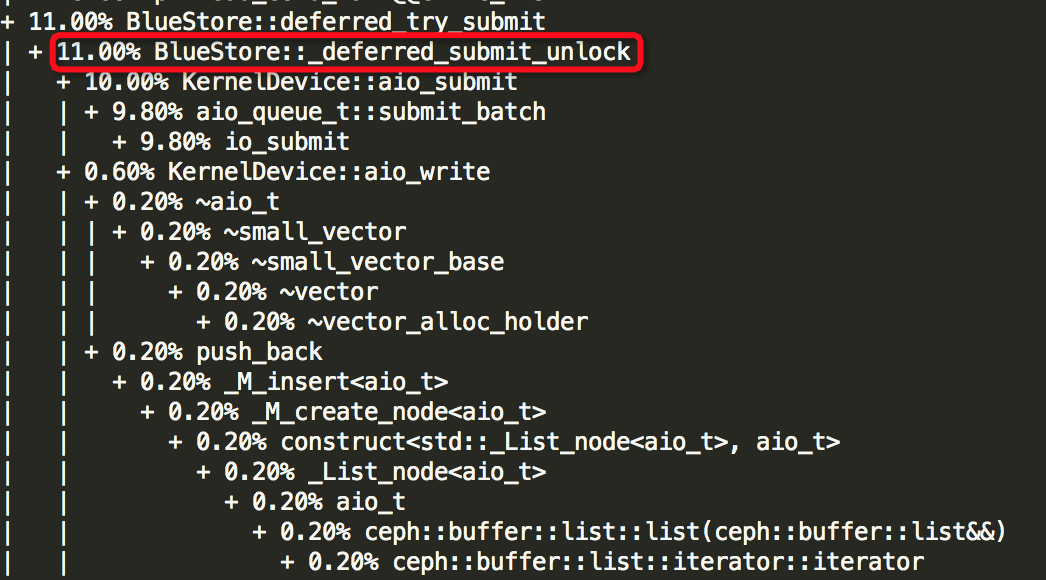
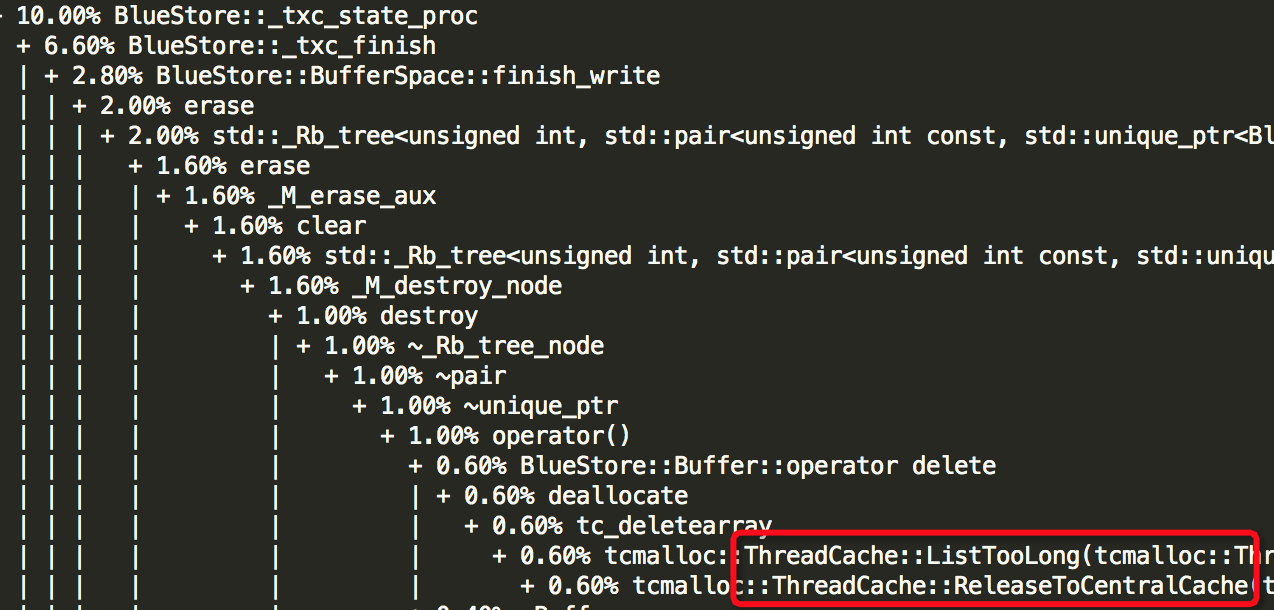
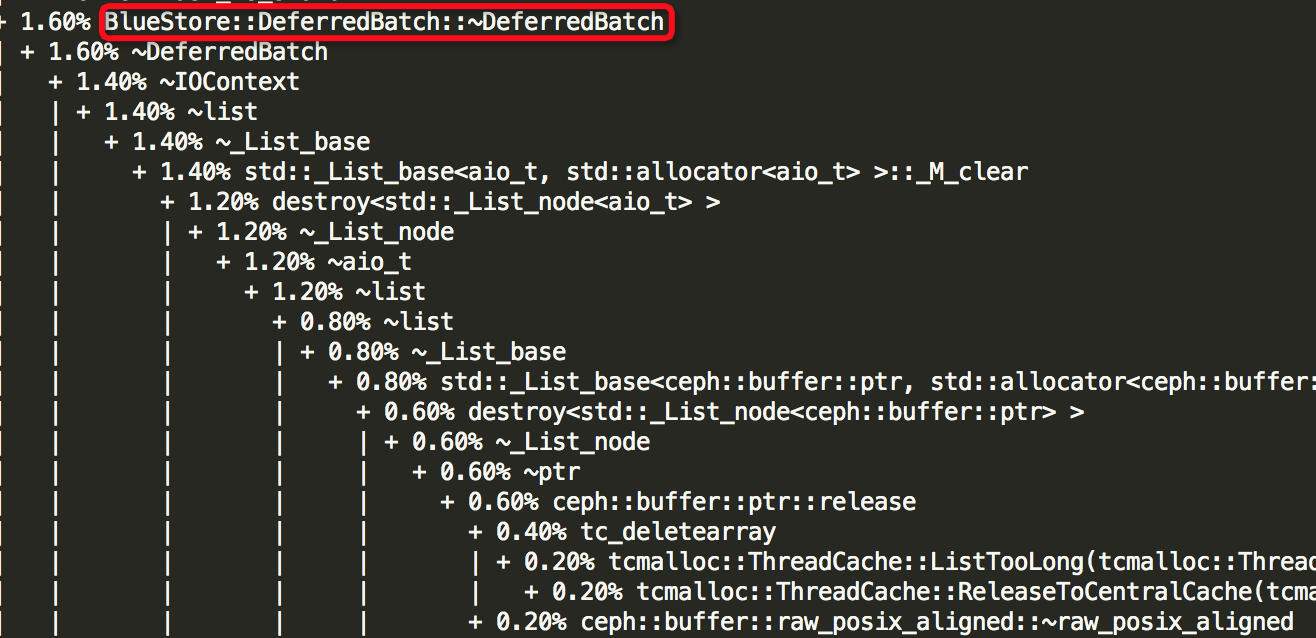
(4)Thread: 52===7972===bstore_kv_sync
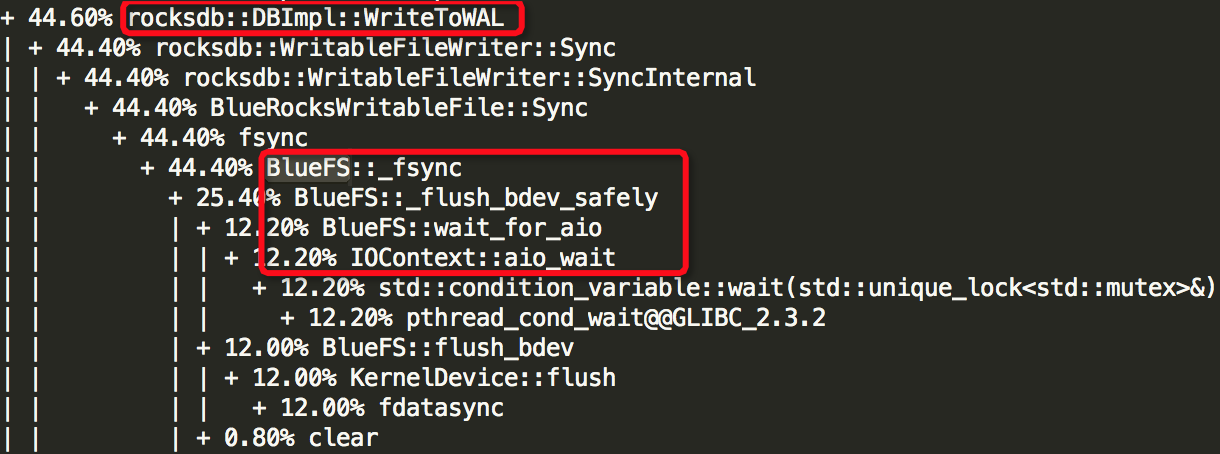
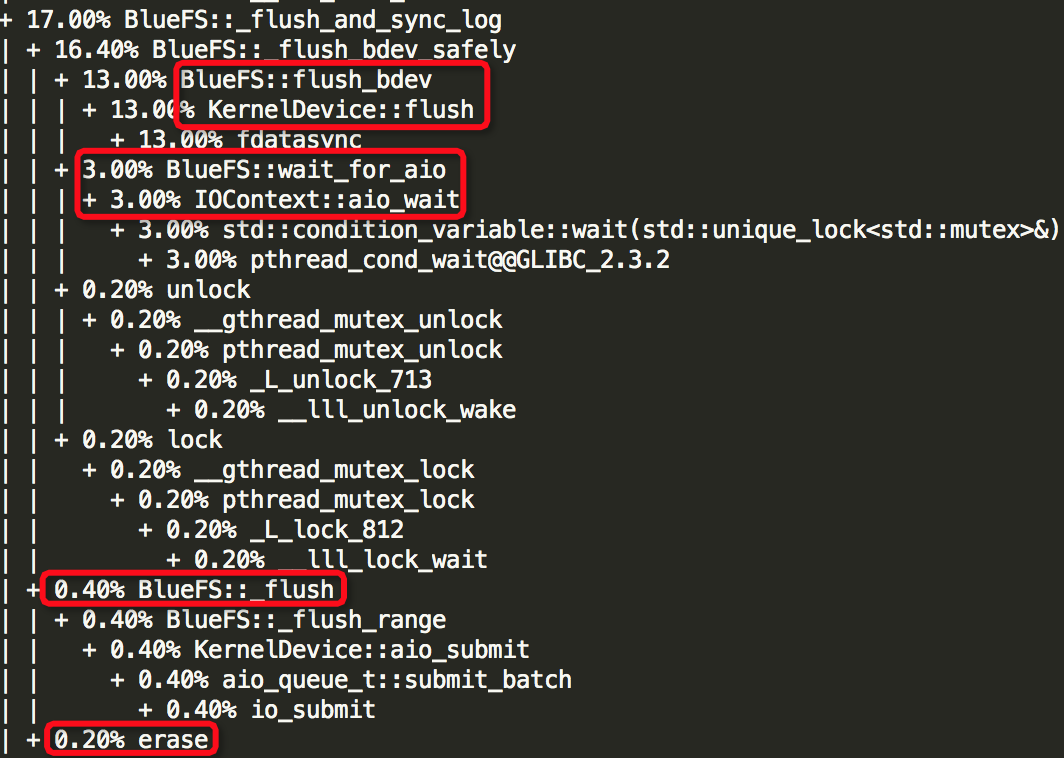
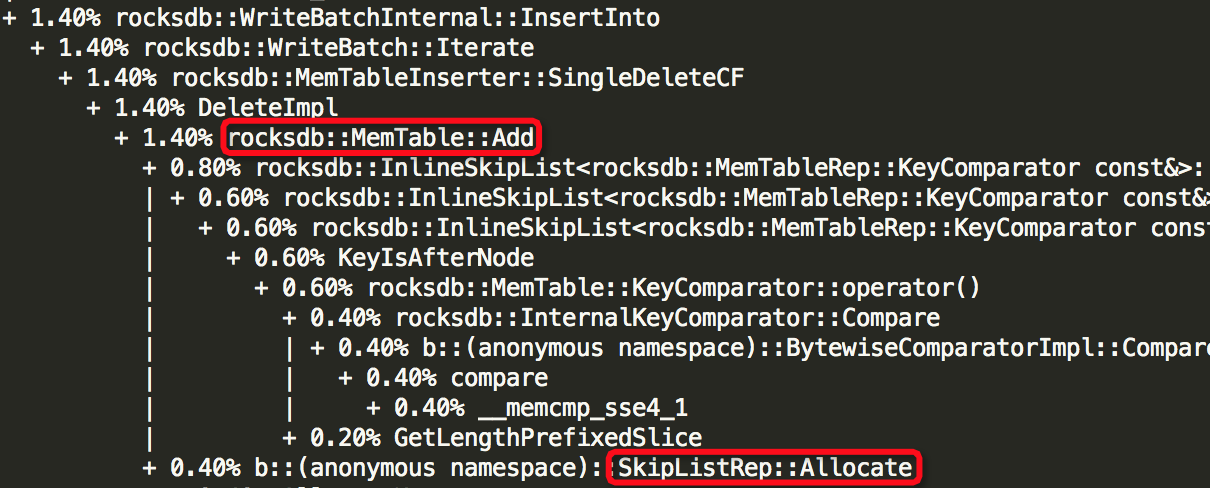
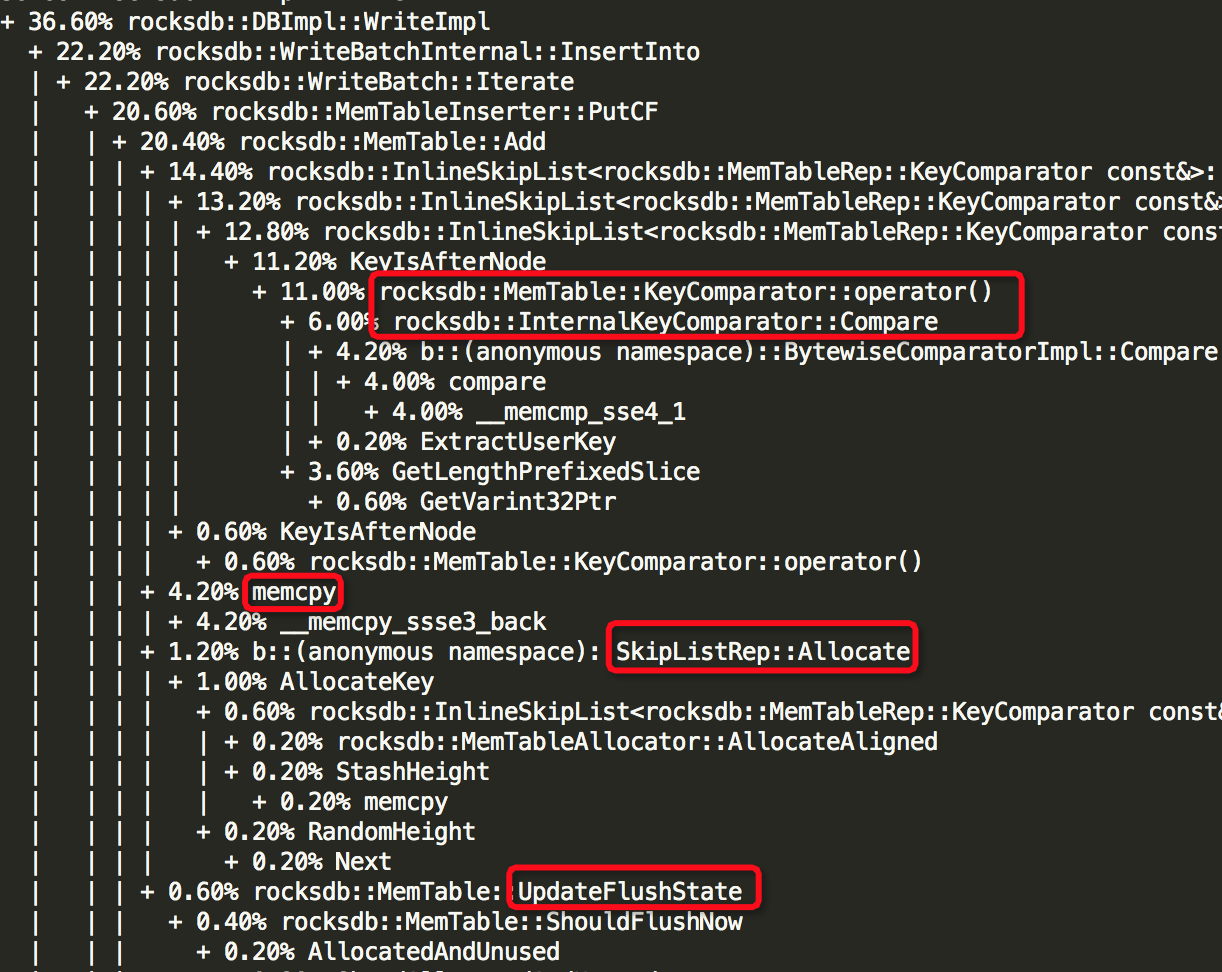
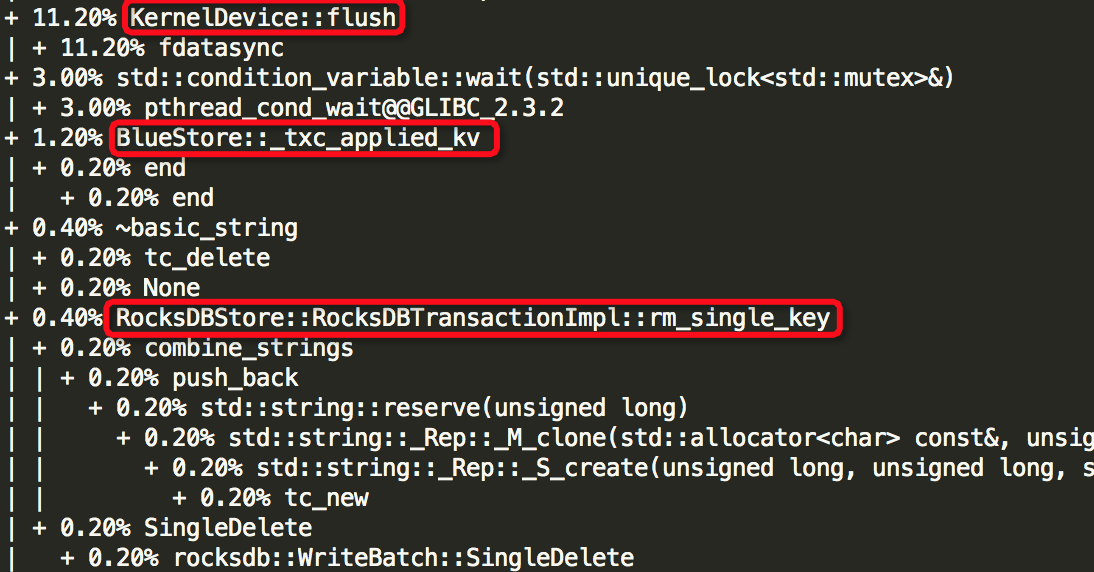
(5)Thread: 53===7971===finisher
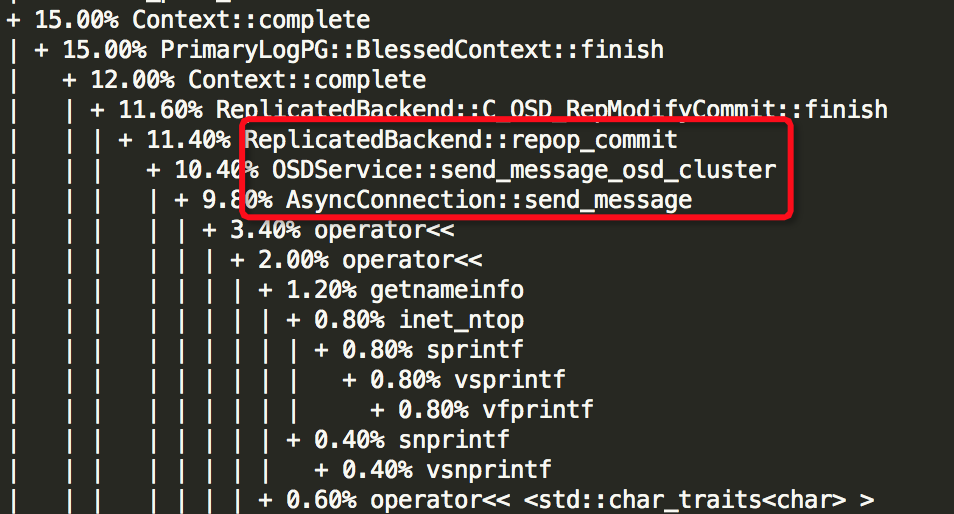
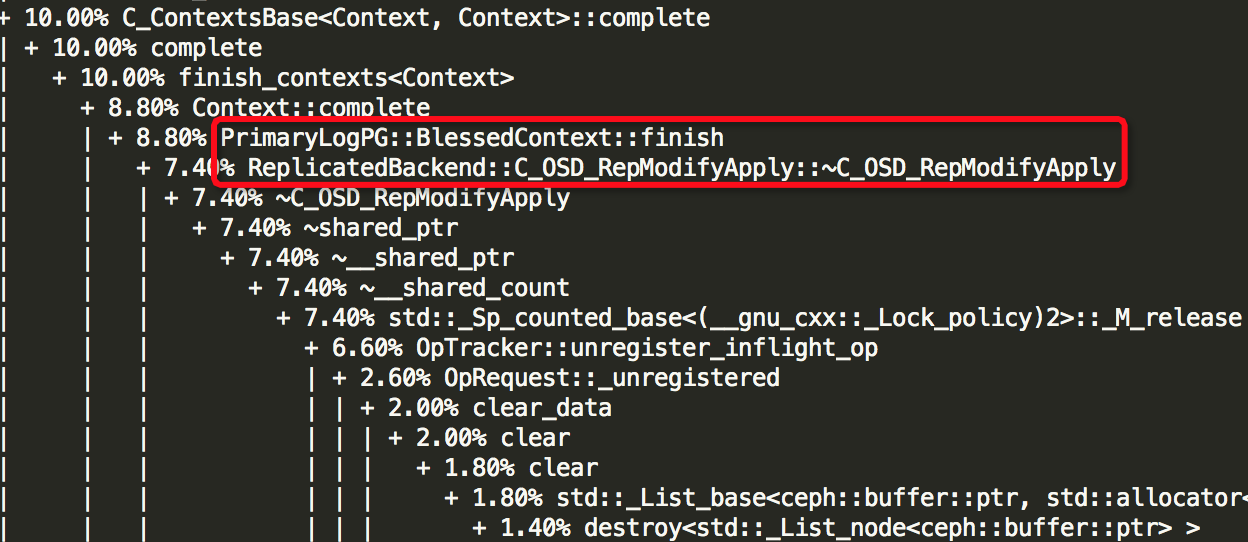
(6)Thread: 68===7926===msgr_worker_0
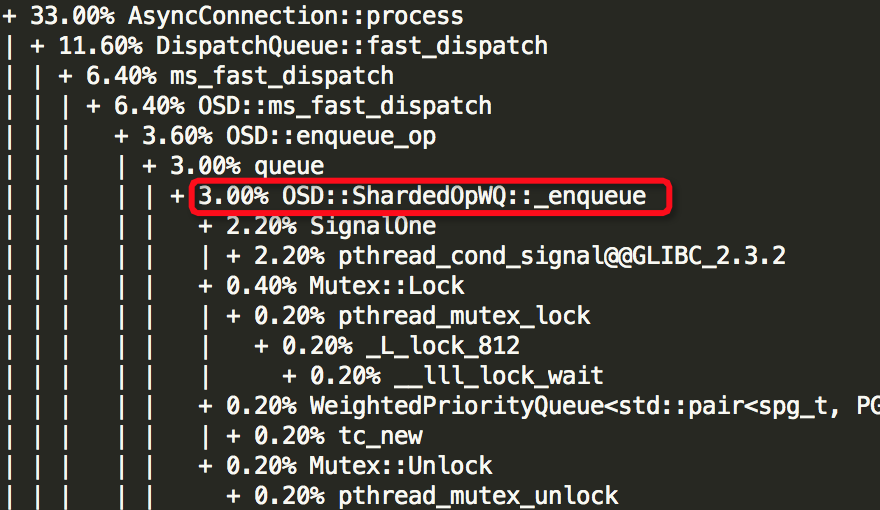
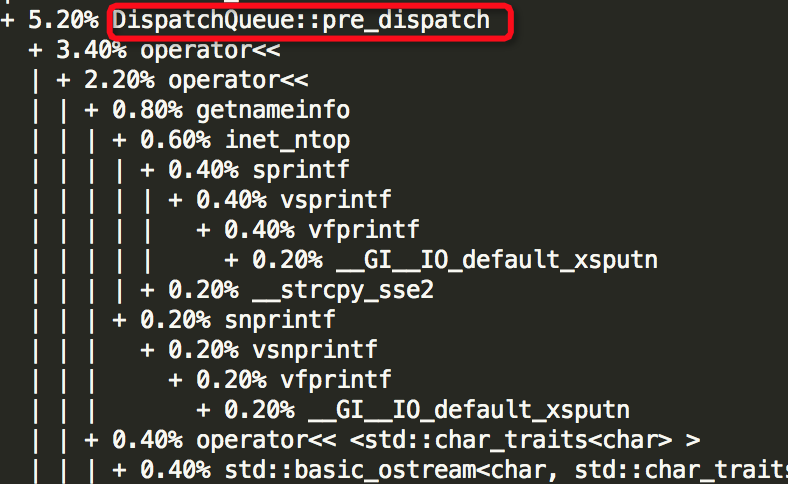
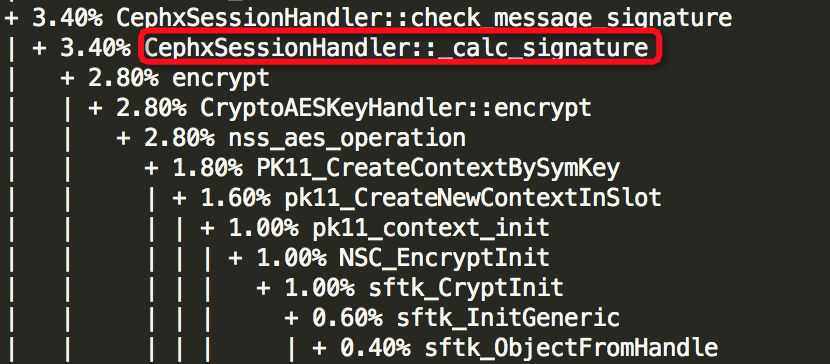
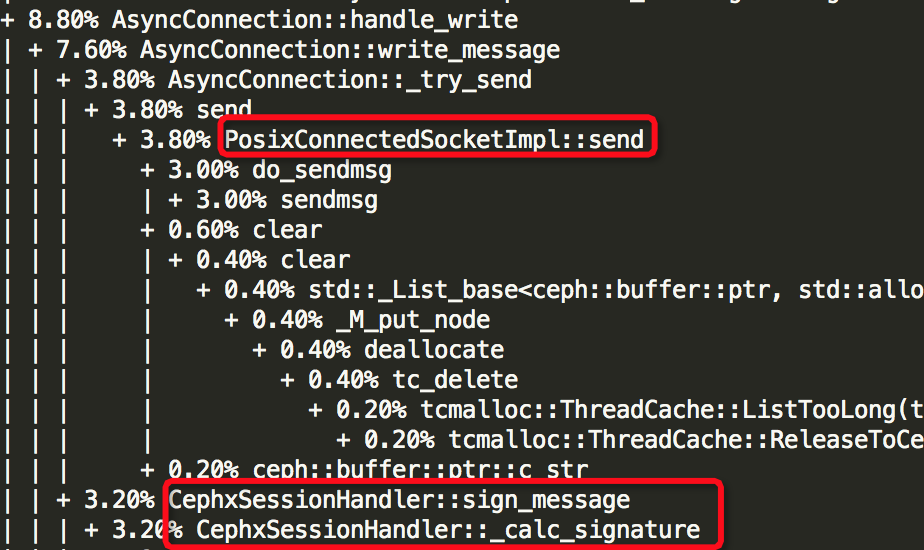
想得到所有69个线程的函数堆栈情况,可去下载